









In Part 1 of this blog series, we talked about what smart AI agents, to truly act like humans, need to process all sorts of data – not just text. We dove into the painful reality: your existing data infrastructure, the one you have Frankensteined together over the years, is simply not cutting it.

We have all seen the ads promising you can build an AI agent in the time it takes to enjoy your morning coffee. Sure it’s possible to create simple agents in just a few hours that handle one or two tasks. But what about more complex, enterprise-grade AI agents? The ones that need to sift through millions of product records, find videos, audio, and instruction manuals tied to those products, and deliver the right information to customers with lightning-fast speed. That’s when the real fun begins.
With the old paradigm you would have to deal with siloed systems, schema nightmares, scalability meltdowns, and query quagmires— turning your agent-building dreams into a constant debugging nightmare. So, if patching together a dozen tools for storage, search, and alignment is a fast track to developer purgatory, how do we bridge this critical gap?
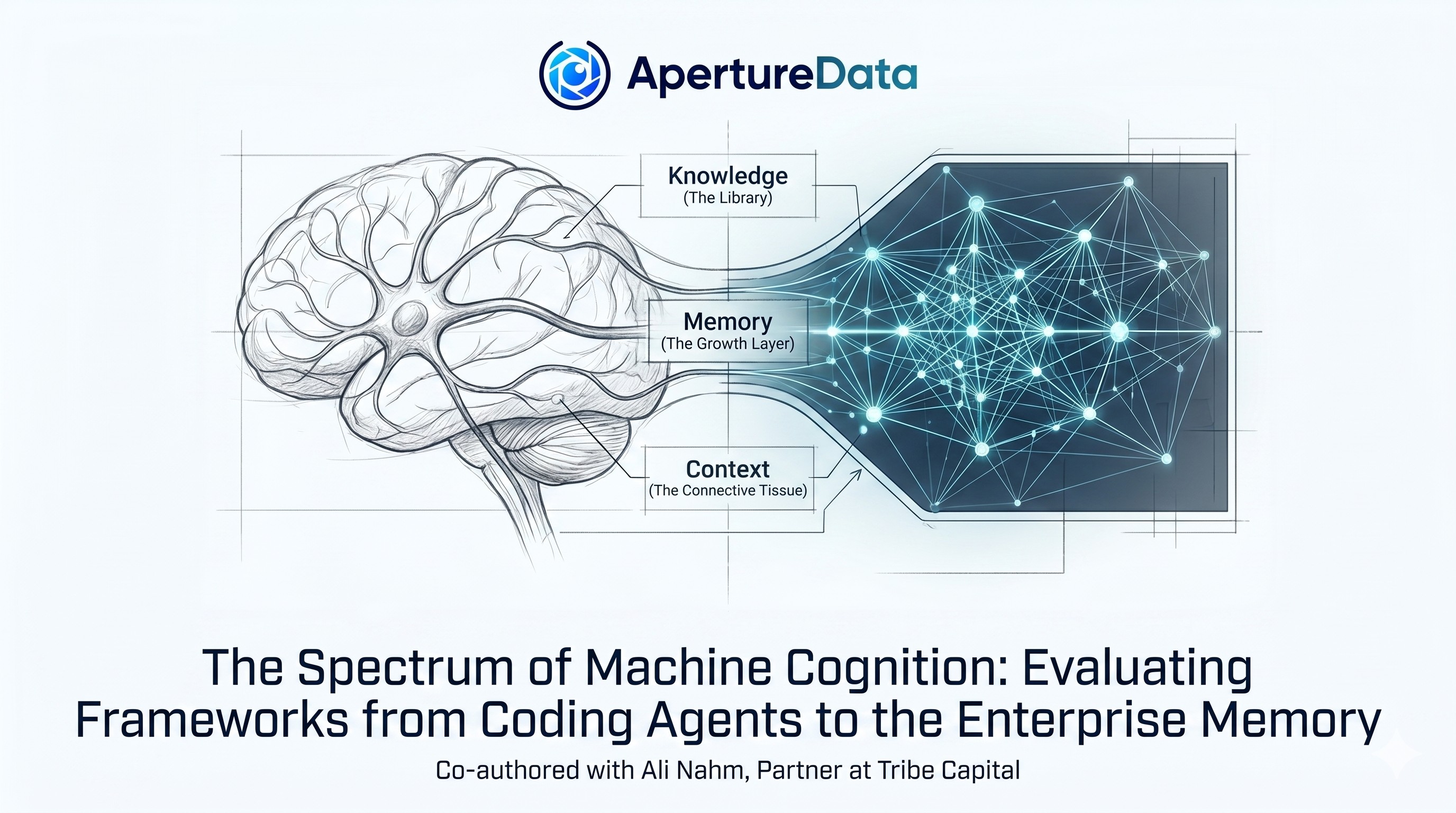
Let’s talk about what every smart AI agent actually needs: a brain. They don’t just answer questions, but also observe, interpret, decide, and act. Modern AI Agents operate more like humans than traditional software, constantly needing to recall and synthesize information to respond intelligently. That means memory isn’t optional—it’s fundamental.
Smart AI agents need to ask:
- “What did the user say last time?”
- “Is this the same object from yesterday’s footage?”
- “What’s the tone in this video clip?”
- “What actions have been taken across different systems?”
Answering these questions requires far more than a simple key-value store or patchwork of point solutions. It demands fast, structured access to rich, multimodal data—text, images, audio, video, embeddings, metadata, and relationships—all woven together into a single, dynamic memory layer.
That is precisely why a new class of purpose-built multimodal databases has emerged. These aren't just vector databases with a fancy new label, nor are they traditional relational databases attempting an AI makeover. They are fundamentally different, and at the forefront of this shift is ApertureDB.
The Smart AI Agent's Unified Brain: Why Multimodal Memory Matters

ApertureDB is engineered specifically for the real-time demands of intelligent, multimodal systems. It’s not just a data store—it’s the central nervous system of your AI agent. Think of it as both the brain and sensory cortex, enabling your agent to perceive, reason, and act across every type of input.
Instead of juggling siloed systems—text in SQL, embeddings in Vector DB, and images and audio in blob storage—ApertureDB brings all modalities together under one roof. And more importantly, it understands how these modalities relate. ApertureDB doesn’t just store data; it models the relationships between them using a graph-based architecture.
For example, a single node in the graph could represent a user, connected to multiple images they have uploaded, the text captions describing those images, the embeddings generated from each, and even the audio commentary they provided. These connections are stored as first-class entities, allowing queries that span modalities—like “Find all users who uploaded images similar to this one and described them with a certain sentiment.”
With native support for vector search, graph queries, and real-time streaming, ApertureDB provides agents with:
- Unified context across modalities
- Fast retrieval for low-latency decisions
- A foundation for reasoning, not just recall
This is what allows your agent to go from reactive to intelligent—from answering questions to understanding the world it operates in.
How ApertureDB Structures Data into Intelligence for AI Agents

Unified Multimodal Data Model—No More Data Silos
Unlike systems where text lives in Postgres, heavy objects in S3, and embeddings in a separate vector store, ApertureDB provides a single, cohesive schema for all your modalities. You can ingest text, video, images, audio, time-series, sensor data, and their associated embeddings and metadata – all in one place.
This multimodal support goes beyond just indexing multimodal embeddings to search and find data by similarity. There is support for access and preprocessing the data in a manner that’s expected by AI applications that really should be multimodal.
This means no more complex ETL pipelines just to correlate a video frame with its transcript and the bounding box of an object detected within it. Data can be inherently linked in the ApertureDB graph by design.
Native Vector + Graph Support—Combining Similarity with Relationships or Context
This is where ApertureDB truly shines beyond simple vector databases. While vector search is fantastic for finding "what looks similar", AI agents often need to know "how things connect" or "what happened before this." ApertureDB integrates native vector indexing for lightning-fast semantic search and native graph capabilities for modeling complex relationships.
Your AI agent can now ask: “Find all frustrated customer interactions—across audio, video, and text—linked to a returned product.” All in a single efficient query, without jumping between disparate systems.
Embedding-Aware Architecture—Optimize Your Multimodal AI Workflows
Embeddings are the digital "fingerprints" of your multimodal data. ApertureDB isn't just a place to dump them; It is designed to understand and leverage them. In ApertureDB, they are not siloed or detached—they are stored directly alongside the original data (images, text, audio, videos) and linked to all relevant metadata via a native graph structure. This embedding-aware architecture preserves context and relationships across modalities, enabling precise and performant queries.
By unifying structured metadata, unstructured content, and embeddings in a single system, ApertureDB eliminates the need for complex pipelines and glue code across SQL, vector stores, and object storage. The result: a simplified data engineering stack that gives agents a coherent, queryable knowledge base for RAG, reasoning, and decision-making across all data types.
Built for Real-World Scale—Sub-10ms Retrieval, Billion+ Entity Scale
ApertureDB is built for the demanding workloads of modern AI agents. Its lightning-fast vector search delivers sub‑10 ms query times across millions of embeddings, while supporting ingestion speeds of 750+ images/sec and managing billions of metadata entities and assets in production. Combined with a memory-aware, low-latency architecture, ApertureDB avoids the crashing and slowing that plague legacy systems under real-world multimodal data loads.
ApertureDB’s core capability, a unified graph-vector database design, perfectly supports advanced memory tools like Mem0. Mem0 combines vector embeddings—which capture semantic meaning—with graph structures that model relationships and context, creating a dynamic and rich short-term memory for AI agents.
ApertureDB natively stores embeddings alongside multimodal data and metadata in a connected graph, allowing agents to efficiently recall, update, and reason over recent interactions in real time.
This architecture doesn’t just help a single agent perform better—it enables multiple AI agents to work simultaneously over the same data, without collisions or slowdowns.
What sets ApertureDB apart is its ability to support multiple agents operating concurrently over a shared knowledge base—a common requirement in enterprise-grade deployments. As agents simultaneously query, update, and reason over large, interconnected datasets, throughput and responsiveness become critical. ApertureDB’s unified architecture ensures what works in your dev environment will scale in production, and your modern AI agents can operate at scale with consistent performance, enabling faster iteration cycles, cross-agent coordination, and the confidence that your AI stack will hold up under pressure—not crumble.
Smarter Agents, Accelerated Development, Real ROI
By adopting a purpose-built multimodal database like ApertureDB, you are not just adding another tool in your stack, but fundamentally transforming your AI development workflow. The payoff:
- Less Glue Code: Focus on building intelligence, not plumbing.
- Faster Iteration: Test, deploy, and refine AI agents in weeks, not quarters.
- Truly Smarter Agents: With real context and real-time decision-making.
- Measurable ROI: Less engineering pain means faster innovation, better user experiences, and infrastructure that actually scales with your AI ambitions.
Next: Modern AI Agents In the Wild
Now that we have covered the “why” and “how”, it’s time to talk about the “who”. In Part 3 of our blog series, we will show how real teams are using ApertureDB to power AI agents that see, think, and act—from RAG applications to website bots. Stay tuned—your agents are about to get a whole lot smarter.
Part 1: Smarter Agents Start With Smarter Data
Part 3: Smart AI Agents in the Wild




















.jpeg)







.png)






