









I think in terms of graphs. I see a person and I retrieve what I know about them like key,value attributes. I see connections among entities in my life like how I know a person or where did I meet them and so on, literally with imaginary lines drawing from A to B to C and so on. For the longest time I thought everyone was like that and we were being forced to map our connected brain objects to the relational world due to the popularity of SQL! In the last few years, I have realized, shockingly, it's not a very large group of people who think in terms of graphs. Our brains have generally been molded to be tabular! In fact, even though graphs are everywhere, from social networks to recommendation engines, they remain one of the most misunderstood data paradigms. While AI and connected systems cry out for structure, context, along with semantics, we continue to force relationships into flat tables and rigid joins. Why did graphs and more importantly graph databases become so confusing and how do we make them simple?
Key Terms in the Graph Data World
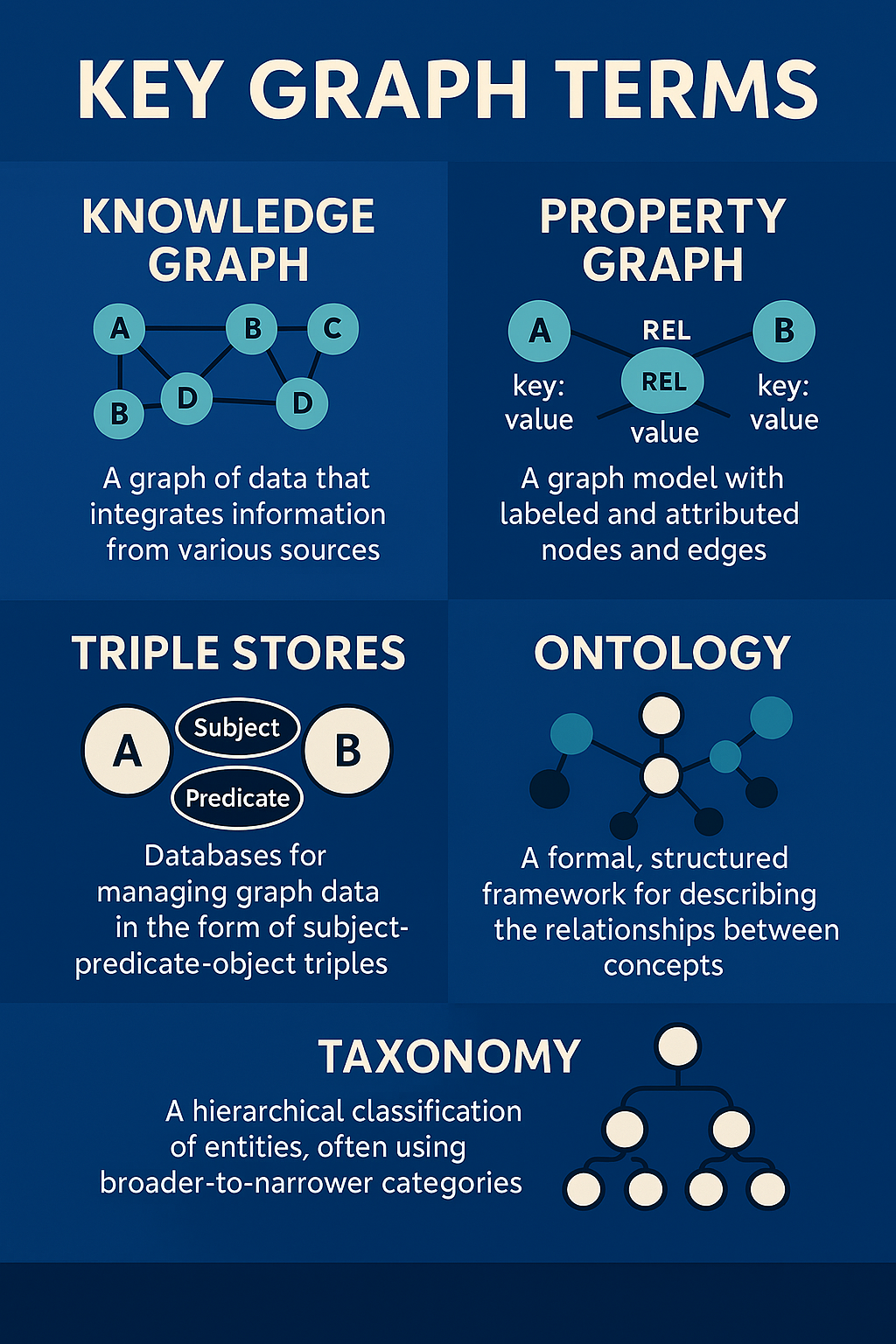
Let’s start with decoding some foundational terminology:
- Knowledge Graphs are a construct that allows us to organize and reason from structured information about entities and their relationships, often used to enable semantic understanding e.g. if Person A is married to B and C manages B’s finances, C must be managing A’s finances as well.
- Property Graphs allow us to represent entities e.g person A, person B, and relationships among them (like A is married to B) as nodes and edges, both of which can hold key-value pairs, providing a way to build a knowledge graph.
- Triple Stores are systems that store data in subject-predicate-object triples, which are essential for RDF-based systems. This approach makes them generic and standardized, and also facilitates the creation of knowledge graphs..
- Ontology defines a formal structure of domain concepts and relationships, acting as a schema for semantic understanding.
- Taxonomy classifies information hierarchically, helping organize entities based on shared characteristics.
Graphs Are Easy, So Why Are We Still Pushing Knowledge into Tables?
Relational databases made sense in the age of forms, invoices, and bank ledgers, but when today’s systems must understand language, images, events, and their interconnected contexts, tabular formats start to crack. Graphs represent relationships natively, and align more naturally with how human and machine intelligence perceive the world.
Still, myths about graphs persist and I feel personally responsible to bust them.
⚠️ Misconception 1: Relational Schemas Are Flexible; Graph Schemas Need Preparation
Many believe relational schemas offer agility, and that graph schemas are rigid or overcomplicated. The reality? Graphs allow emergent structure; relationships and entities can evolve without destructive migrations. Schema-less or schema-light graph databases let you build incrementally while preserving semantic richness. Flexibility isn’t just possible, it’s native. In fact, we have occasionally run into the opposite problem where people who understand graphs and have dabbled in graph databases find them too flexible and need to build restrictions into the graph loaders, which can actually be accomplished easily as well.
🐢 Misconception 2: Graph Databases Are Slow
“Graphs are too slow for production” is a dated view, stemming from early implementations, especially from Java-based implementations and disk-based traversals. It’s very much possible today to build memory optimized graph databases like what ApertureDB provides, for speed with:
- In-memory data structures and cache-optimized traversals with memory first design
- Index-free adjacency to enable fast traversal over connections to explore neighborhoods of broader information
- Parallel query execution
And with hybrid graph+vector systems, semantic search and reasoning can be near real-time, even across multimodal data (we have measured 15msec lookup time for a billion scale graph with ApertureDB).
📈 Misconception 3: Graph Databases Don’t Scale
Scale is often equated with horizontal sharding and billions of rows but graph databases, when built well, can easily handle:
- Billions of entities and edges
- Distributed storage and compute, especially when graph patterns and edge distributions are correctly managed
- Query patterns optimized for traversal
Modern graph platforms can scale contextually, connecting depth and breadth without sacrificing performance.
Common Questions Surrounding Graph Construction
Even as graphs gain traction, many users still ask: Where do I start? What goes into a graph? Can I build one automatically? Let’s tackle the most common questions we hear.
📦 What Goes in my Knowledge Graph?
At its core, a graph stores entities (nodes) and relationships (edges). But what qualifies?
- Entities: Person, product, document, image, sensor, event - anything with identity.
- Relationships: Friend-of, part-of, located-in, derived-from, similar-to, embeddings-of - anything that connects or contextualizes.
You can also attach properties or attributes to both nodes and edges: timestamps, labels, and more - basically, any metadata about whatever is being represented in the graph. The goal is to capture structure and semantics, not just raw data. Most graph databases make it easy to search by the type of entity and value of attributes e.g. “find any person who was born after 2000” or by their relationship to each other e.g. “find all friends-of Kara”.
🧩 Users Already Have Graph Data
Here’s the twist: most users already have graph-shaped data, they just don’t call it that.
- A customer table linked to orders? That’s a graph.
- A document referencing other documents? Graph.
- A multimodal dataset with images, captions, and tags? Definitely a graph.
The challenge isn’t creating graphs from scratch, it’s recognizing and unlocking the graph that’s already there. Once you map the existing data to a graph, as new data is made available, you can continue to add it to the graph database like with any other database. Over time, with the added relations and entities, you start to assemble your "knowledge" base that can then be queried for deeper insights e.g. does a person have a big family by counting family relations originating from that person's node in the graph.
🤖 Can You Generate a Graph for Me?
Yes… and increasingly, Large Language Models or LLMs and AI tools can help automate graph construction.
- From structured data: infer entities and relationships from tables, logs, or APIs.
- From unstructured data: extract concepts and links from text, images, or video.
- From multimodal sources: unify disparate modalities into a coherent graph.
Overall, LLMs are becoming powerful allies in graph construction by assisting with:
- Entity extraction: Identify key concepts from text and other data types.
- Relationship inference: Predict how entities relate based on context.
- Schema suggestion: Recommend graph structures based on domain knowledge.
- Query generation: Translate natural language into graph queries.
LLMs don’t replace graph design, they accelerate and augment it. This can be tricky to get right, which is where entity resolution is a major area of research in itself.
🔄 Can I Map Any Objects in This Graph?
Yes, graphs are schema-flexible and modality-agnostic. You can map:
- Text, images, audio, video
- Structured records and logs
- Embeddings and model outputs
- External APIs and knowledge bases
If it has identity and context, it can live in a graph. The key is defining them in a manner that matters to your application.
A note on what it means to map multimodal objects like text, images, PDFs, audio, video and so on: typically, in databases like ApertureDB, it means introducing a node that represents those data types and linking to the corresponding files in storage. You can of course choose to embed the content as an attribute of the node but that requires some accessibility optimizations. However, with all the metadata captured in the graph node representing the multimodal object, it's quite feasible to search fast and access them efficiently and at scale. It also opens up the possibility of representing derived objects like bounding boxes for images, clips or frames for videos, or paragraphs for documents as connected nodes in the graph of multimodal data.
Clearing the Air, Simplifying Graphs
When you need a large team to create a wannabe graph on top of relational or key-value databases (remember Tao on MySQL?), or when your data storage fits naturally in a graph but you are forced to spend resources in generating relational tables from it to save folks from dealing with graphs, it begs the question, why not migrate to a graph database and invest in removing these misconceptions about them!
Graphs aren't exotic. They’re just data plus context. And as AI systems become more perceptual, relational, and multimodal, graph-native thinking will be key.
It’s not about replacing relational databases. It’s about knowing when and where to shift paradigms, from flat to dimensional, from records to relationships, from storage to contextual memory.




















.jpeg)







.png)






