



.png)





Part 1 – Data Schema, Embeddings, And Graph Design For An Agentic Query Engine On ApertureDB
It’s not uncommon to have a collection of mixed data types like documents, slides, images, videos and their corresponding titles and descriptions dumped in folders or listed on webpages most commonly by dates and events. What if you don’t actually recall the year something was created? What if you wanted to cross-reference a few of those documents and descriptions based on some criteria or to find patterns? That’s what we are here to solve. To demonstrate the simplicity and flexibility of doing this, we have chosen the very common case of event data, in this case, with our partners, MLOps World. The data encompasses talks from MLOPs World conferences across three years. Our tool-equipped AI Query Agent is able to navigate rich interconnected data stored in ApertureDB, an AI-native multimodal vector-graph database, to answer natural language queries effectively and accurately.
Dataset: MLOps Conference Talks from 2022-2024 (.csv)
Embedding model: EmbeddingGemma by Google
Platform: Google Colab (CPU or T4 GPU)
Metadata, text and vector storage: ApertureDB
Event Agent: try out the agent
GitHub Repository: Repo
Data Architecture & Pipeline
Conference content represents the following data challenge: hundreds of talks spanning multiple years, each with metadata, transcripts, speaker information, PDFs or powerpoints of the presentations, and video recordings, with no good way to search and find talks without clicking on multiple links to navigate pages and pages of dense information. Traditional keyword search falls short when users want to ask questions like "Which talks discuss AI agents with memory?" or "Find presentations about RAG from Databricks engineers." Answering these queries requires more than just storage or a table of talk information; it demands a navigable cognitive map. For an AI agent to effectively function as a domain expert, the underlying data architecture must be designed from the ground up to support natural language traversal, allowing the LLM to decompose complex user intent into precise, executable graph and/or vector search based queries or operations.
This is Part 1 of a multi-part series documenting the construction of an AI-powered search platform for MLOps World and GenAI World conference talks. This post focuses entirely on the data foundation: schema design decisions that enable intelligent query decomposition, embedding strategies, and the graph structure that allows an LLM to translate natural language into efficient database operations. Part 2 will cover how these query patterns become tools for a LangGraph-based ReAct agent. In the later parts, we will dive into a very exciting feature - semantic search across conference talk videos and the granularity with which it enables extracting meaningful information from raw videos.
We have implemented the different parts of the data pipeline in separate Colab notebooks. We have included some core code snippets in this blog. You can find the complete codebase in the linked notebooks in each section. This Github repo has the entire application code along with the notebooks.
The Dataset
The source data consists of talk submissions from MLOps World and GenAI World conferences (2022-24). After deduplication and filtering for talks with available YouTube recordings, the working dataset has 280 unique talks from 263 speakers across companies including Google, Microsoft, Meta, Databricks, and over 100 others. We can enrich the talk information further via Apify on YouTube with additional metadata: view counts, publish dates, and timestamped transcript segments that would later enable precise video linking from search results. This is a two step process. The first notebook shows the data cleaning operations whereas the second notebook deals with the enrichment by mixing information extracted from youtube.
Schema Design: Engineering for LLM Query Decomposition
The schema represents the most consequential decision in the entire pipeline. In the context of Agentic RAG, the schema acts as the agent's long-term memory structure. If the data is stored flatly, the agent is forced to rely on broad, inefficient vector searches. By modeling the domain as a graph, we effectively pre-compile the reasoning paths (e.g., Speaker → Talk → Topic) that the agent will need to navigate. This significantly reduces the risk of hallucinations and retrieval errors as the agent doesn’t have to rely solely on the semantically retrieved text chunks to make assumptions about concepts and relationships, rather it can use tools to perform more complex database (DB) queries including filters and graph traversals to find nuanced data as needed.
Consider what happens when a user asks: "Find talks about model monitoring from speakers at financial companies." An LLM agent must: (1) identify that "model monitoring" requires semantic search across transcript or talk video/document content, (2) recognize that "financial companies" implies a metadata filter on company names, and (3) understand that results need to join back to talk entities for display. A flat table structure would require complex application logic to orchestrate these operations. A well-designed graph structure makes this a natural traversal which can be converted to a parametrised tool that an AI agent can use directly with specified dynamic parameters. We will describe how we create these tools in Part 2 of this blog series.
The diagram below depicts an overview of the schema for a high-level idea before we dive into the details regarding the schema construction:
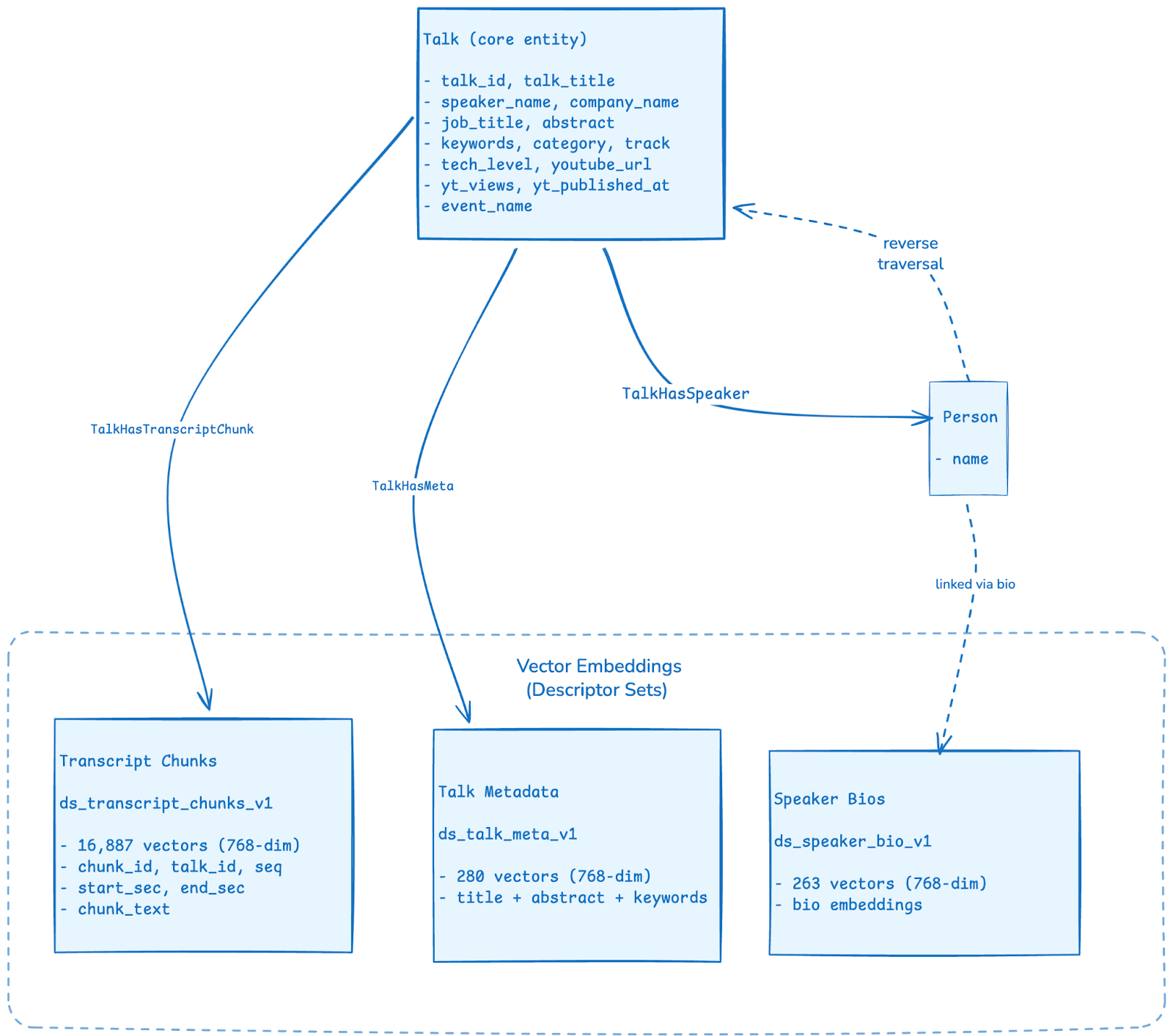
An interesting thing about our schema and ApertureDB’s flexibility is that we can easily add in as much data as we want and evolve the schema as needed. This will allow us to add data related to Talks in upcoming years and the AI Agent will automatically have insights into the latest data without needing to modify the tools or anything else - just ingest the data!
Entity Classes: Designed for Query Patterns
ApertureDB's graph database capabilities enable modeling the domain as interconnected entities. Each entity class is designed with specific query patterns in mind:
Talk: is the central entity class, serving as the hub for all traversals. For an AI agent operating within a limited context window, the ability to filter data before retrieval is critical. By typing properties strictly (e.g., integers for views, dates for timestamps), we enable the agent to write precise metadata filters (e.g., views > 500) rather than relying on fuzzy semantic matching, ensuring that the retrieved context is high-quality and token-efficient. Properties were selected based on anticipated filter and sort operations:
properties = {
"talk_id": talk_id, # Deterministic UUID for idempotent operations
"talk_title": talk_title, # Unique constraint for lookups
"speaker_name": speaker_name, # Denormalized for display (normalized via Person entities)
"company_name": company_name, # Enables "talks from Company X" filters
"job_title": job_title, # Enables role-based filtering
"abstract": abstract, # Rich text for context
"what_youll_learn": outcomes, # Structured learning outcomes
"keywords_csv": keywords, # Enables keyword-based filtering
"category_primary": category, # Categorical filtering
"track": track, # Conference track filtering
"tech_level": tech_level, # Integer 1-7 for difficulty filtering
"youtube_url": youtube_url, # Direct link for results
"youtube_id": youtube_id, # Enables video entity joins
"yt_views": int(views), # Integer type enables sorting/comparison
"yt_published_at": {"_date": iso_date}, # Native date type for range queries
"event_name": event_name, # Conference year/edition filtering
"bio": speaker_bio, # Speaker context for relevance
}
The type decisions matter significantly for downstream AI agent tools. Storing yt_views as an integer (not a string) enables an agent to generate queries like "talks with more than 10,000 views" using numeric comparison operators. The yt_published_at field uses ApertureDB's native date type, enabling range queries that an AI agent can express as "talks from 2024" or "presentations in the last 6 months." These seemingly small decisions directly determine what natural language patterns the agent can handle and how efficiently.
Person: Speaker entities exist as separate nodes rather than embedded strings, a decision driven entirely by query requirements:
{"AddEntity": {
"class": "Person",
"if_not_found": {"name": ["==", speaker_name]},
"properties": {"name": speaker_name}
}}The source data stored speakers as comma-separated strings: "Ravi Chandu Ummadisetti, Stephen Ellis, Kordel France, Eric Swei". Maintaining this format would force "find all talks by Speaker X" to use substring matching - unreliable, slow, and difficult for an AI agent to express correctly. As separate entities with explicit relationships, speaker queries become graph traversals which can in turn be provided as tools to the AI agent: "find Person where name equals X, then traverse its connection to the Talks class to get the Talk it is associated with."
Multi-Speaker Normalization
We had to carefully handle transforming comma-separated speaker strings into proper graph relationships. For an LLM, string manipulation is error-prone. By normalizing speakers into distinct entities during ingestion, we remove the burden of entity resolution from the agent at runtime. The agent interacts with a clean Person object, not a messy string, ensuring that queries about specific experts yield comprehensive and accurate results.
For each talk, the ingestion pipeline executes an atomic transaction that: (1) locates the Talk entity, (2) creates Person entities with if_not_found semantics to prevent duplicates, and (3) establishes TalkHasSpeaker connections:
# Atomic transaction: find talk, create speaker, create connection
[
{"FindEntity": {
"with_class": "Talk",
"_ref": 1,
"constraints": {"talk_title": ["==", talk_title]}
}},
{"AddEntity": {
"class": "Person",
"_ref": 2,
"if_not_found": {"name": ["==", speaker_name]},
"properties": {"name": speaker_name}
}},
{"AddConnection": {
"class": "TalkHasSpeaker",
"src": 1,
"dst": 2,
"if_not_found": {} # Idempotent - won't create duplicate edges
}}
]The result: 338 Person entities and 373 TalkHasSpeaker connections (some speakers presented multiple talks across conferences). ApertureDB's if_not_found clause on both entities and connections ensures complete idempotency - the pipeline can be re-executed during development without creating duplicates, a significant advantage when iterating on schema design.
Deterministic Identifiers for Reproducible Pipelines
Generating stable, deterministic identifiers proved essential for pipeline reliability. Random UUIDs would cause re-runs to create duplicate entities. UUID5 with a stable composite key ensures identical input always produces identical identifiers:
def make_talk_id(talk_title: str, youtube_id: str) -> str:
base = f"{(talk_title or '').strip()}|{(youtube_id or '').strip()}"
return str(uuid.uuid5(uuid.NAMESPACE_URL, base))Combined with if_not_found constraints throughout the ingestion pipeline, this approach makes the entire data layer reproducible- essential when debugging issues or evolving the schema during development.
The complete code for data ingestion can be found in this notebook.
Text Embedding Strategy: Chunking for Precision
Semantic search requires vector embeddings, and the embedding strategy involves three interconnected decisions: model selection, chunking approach, and index configuration.
Model and Chunking Design
The google/embeddinggemma-300m model produces 768-dimensional vectors with strong semantic understanding. For transcript content, we implement a segment-based chunking strategy rather than character-based splitting:
CHUNK_LEN = 10 # Transcript segments per chunk
OVERLAP = 2 # Overlapping segments between chunks
STRIDE = CHUNK_LEN - OVERLAP # 8 segments advance per chunk
def chunk_transcript(transcript_items: list, talk_id: str) -> list:
chunks = []
seq = 1
for i in range(0, len(transcript_items), STRIDE):
segment = transcript_items[i:i + CHUNK_LEN]
start_sec = timestamp_to_seconds(segment[0].get("timestamp", "0:00"))
end_sec = timestamp_to_seconds(segment[-1].get("timestamp", "0:00"))
chunk_text = " ".join([s.get("text", "").strip() for s in segment])
chunks.append({
"chunk_id": f"{talk_id}#ch{seq:04d}",
"talk_id": talk_id,
"seq": seq,
"start_sec": int(start_sec),
"end_sec": int(end_sec),
"chunk_text": chunk_text,
})
seq += 1
return chunksThis approach offers two advantages over character-based chunking. First, it preserves natural speech boundaries; chunks align with how speakers actually structure their content. Second, the preserved timestamps (start_sec, end_sec) enable a powerful UX capability: search results can deep-link directly to the relevant moment in the source video, transforming semantic search from "this talk mentions X" to "this exact 30-second segment discusses X."
The 2-segment overlap prevents context loss at chunk boundaries, ensuring concepts that span segment boundaries remain searchable.
Connection Classes: The Key to Natural Language Traversal
The real power of graph modeling for LLM agents emerges from explicit, typed relationships. These connections effectively physicalize the agent's 'Chain of Thought.' When an agent needs to answer 'What else has this speaker discussed?', it doesn't need to guess; it simply traverses the TalkHasSpeaker edge. This transforms abstract reasoning into deterministic graph traversal. ApertureDB provides powerful connection and traversal capabilities. Each connection class encodes a traversal pattern that maps to natural language query components:
TalkHasSpeaker: Bidirectional traversal between Talk and Person entities. This single connection class enables multiple query patterns:
- "All talks by [speaker name]" → Find Person, traverse outward to Talks
- "Who presented about [topic]?" → Semantic search for topic, traverse results to connected Persons
- "Other talks by speakers who discussed [topic]" → Chain: semantic search → Talk → Person → Talk
TalkHasTranscriptChunk: Links Talk entities to their transcript chunk embeddings (which is expanded upon in the next section). This connection is essential for constrained semantic search, one of the most powerful patterns for AI agents. Rather than searching all 16,887 transcript chunks globally, queries can first filter talks by metadata (date range, speaker, category, view count), then search only within those talks' connected chunks. This dramatically improves relevance for queries like "recent talks about Kubernetes" or "beginner-level content on MLOps."
TalkHasMeta: Links Talk entities to aggregated metadata embeddings (title + abstract + keywords). This enables semantic search at the talk level rather than chunk level - useful for high-level topic discovery before diving into specific content.
This schema embodies a design principle: most of the anticipated natural language query pattern should decompose into a combination of property filters, graph traversals, and vector searches expressible in ApertureDB's query language. The schema itself encodes the query semantics that the AI agent will exploit through a suite of tools.
Connected Embeddings: The ApertureDB Advantage
ApertureDB organizes embeddings into descriptor sets - indexed vector collections optimized for similarity search. Three descriptor sets serve different search intents:
# Transcript chunks - detailed content search (16,887 vectors)
utils.add_descriptorset("ds_transcript_chunks_v1", dim=768, metric=["CS"], engine="HNSW")
# Talk metadata - high-level topic discovery (280 vectors)
utils.add_descriptorset("ds_talk_meta_v1", dim=768, metric=["CS"], engine="HNSW")
# Speaker bios - expertise-based search (263 vectors)
utils.add_descriptorset("ds_speaker_bio_v1", dim=768, metric=["CS"], engine="HNSW")The HNSW (Hierarchical Navigable Small World) index provides fast approximate nearest neighbor search, while cosine similarity (CS) is appropriate for normalized text embeddings.
The critical capability and a key differentiator of ApertureDB's architecture is that each embedding connects to its source entity within the same database:
{
"AddDescriptor": {
"set": "ds_transcript_chunks_v1",
"properties": {
"chunk_id": chunk_id,
"talk_id": talk_id,
"seq": seq,
"start_sec": start_sec,
"end_sec": end_sec,
"chunk_text": chunk_text,
},
"if_not_found": {"chunk_id": ["==", chunk_id]},
"connect": {
"class": "TalkHasTranscriptChunk",
"ref": 1,
"direction": "in"
}
}
}This connection enables constrained semantic search in a single query, a pattern very complex to replicate with separate vector and relational databases:
# Single query: filter talks by event, then semantic search within those talks' chunks
[
{"FindEntity": {
"with_class": "Talk",
"_ref": 1,
"constraints": {
"event_name": ["==", "MLOps & GenAI World 2024"]
},
{"FindDescriptor": {
"set": "ds_transcript_chunks_v1",
"k_neighbors": 20,
"is_connected_to": {"ref": 1, "connection_class": "TalkHasTranscriptChunk"}
}}
]Processing 278 talks yielded 16,887 transcript chunks. ApertureDB's ParallelLoader completed ingestion in approximately 4 minutes at 71.5 items/second, including both embedding storage and connection creation in atomic transactions. Quite fast for the large amount of data!
The complete code for embeddings’ generation + ingestion into ApertureDB DescriptorSets can be found in this notebook.
Query Patterns That Define Tool Capabilities
Before implementing any agent logic, the data layer needs to be validated against anticipated query patterns. Each pattern maps directly to a tool the AI agent will use. We will discuss the tools in detail in the next part, but for now, let’s take a look at some of the tested queries:
Metadata Filtering
[{"FindEntity": {
"with_class": "Talk",
"constraints": {
"yt_published_at": [">=", {"_date": "2024-01-01"}],
"yt_views": [">", 10000],
"tech_level": ["<=", 3]
},
"sort": {"key": "yt_views", "order": "descending"},
"limit": 10,
"results": {"list": ["talk_title", "speaker_name", "yt_views", "abstract"]}
}}]Speaker Graph Traversal:
[
{"FindEntity": {
"with_class": "Person",
"_ref": 1,
"constraints": {"name": ["==", "Michael Haacke Concha"]}
}},
{"FindEntity": {
"with_class": "Talk",
"is_connected_to": {"ref": 1, "connection_class": "TalkHasSpeaker"},
"results": {"list": ["talk_title", "event_name", "abstract", "youtube_url"]}
}}
]The result returns the Talk associated with this speaker:
{
"FindEntity": {
"entities": [
{
"abstract": "This talk explores how LATAM Airlines leveraged MLOps to revolutionize their operations and achieve financial gain in the hundred of millions of dollars. By integrating machine learning models into their daily workflows and automating the deployment and management processes, LATAM Airlines was able to optimize tariffs, enhance customer experiences, and streamline maintenance operations. The talk will highlight key MLOps strategies employed, such as continuous integration and delivery of ML models, real-time data processing. Attendees will gain insights into the tangible benefits of MLOps, including cost savings, operational efficiencies, and revenue growth, showcasing how strategic ML operations can create substantial value in the airline industry.",
"event_name": "MLOps & GenAI World 2024",
"talk_title": "Revolutionizing the skies: Mlops case study of LATAM airlines",
"youtube_url": "https://www.youtube.com/watch?v=h6X7Cbo_-ho"
}
],
"returned": 1,
"status": 0
}
}Semantic Search with Automatic Join:
[
{"FindDescriptor": {
"set": "ds_transcript_chunks_v1",
"_ref": 1,
"k_neighbors": 20,
}},
{"FindEntity": {
"with_class": "Talk",
"is_connected_to": {"ref": 1, "connection_class": "TalkHasTranscriptChunk"},
"results": {"all_properties": True}
}}
]Response for query “Which talks referred to AI agents?”:
[{'FindDescriptor':
{'entities': [
{'_distance': None, 'chunk_id': '4b5ed1f3-6dc6-5b0f-9dfb-03f9e027f218#ch0015', 'chunk_text': 'engineering so in conclusion AI tools are transformative but they need proper oversight to avoid chaos while AI might not be perfect with a correct security measures in place like guardrails you can confidently harness its power and enjoy the wonders of AI thank you', 'end_sec': 282, 'seq': 15, 'start_sec': 282, 'talk_id': '4b5ed1f3-6dc6-5b0f-9dfb-03f9e027f218'},
{'_distance': None, 'chunk_id': '14b1947c-c2ac-5777-8a3b-4593460325f7#ch0001', 'chunk_text': "[Applause] [Music] yep thanks everyone so nice to meet you Michael triffle here with Rea AI um so to rea the future of AI is multimodal so our mission is to develop Next Generation AI to empower the most capable agents that can see hear as well as speak we'll play a little", 'end_sec': 38, 'seq': 1, 'start_sec': 0, 'talk_id': '14b1947c-c2ac-5777-8a3b-4593460325f7'},
...]Constrained Semantic Search:
# First filter by metadata, then semantic search only within matching talks
[
{"FindEntity": {
"with_class": "Talk",
"_ref": 1,
"constraints": {"company_name": ["==", "Google"]}
}},
{"FindDescriptor": {
"set": "ds_transcript_chunks_v1",
"k_neighbors": 10,
"is_connected_to": {"ref": 1}
}}
]Each of these patterns executes as a single atomic transaction. ApertureDB's unified architecture - combining graph traversal, vector search, and property filtering in one system - eliminates the latency and consistency challenges of orchestrating separate databases.
These are only a few of the queries that we tested. For an almost exhaustive list of queries check out the full code in the Colab notebook.
The Unified AI-Native Architecture
Why did we choose to build a complex agentic search solution on ApertureDB? The platform uniquely combines capabilities that would otherwise require multiple specialized systems:
- Graph database for entity relationships, multimodal representation, and multi-hop traversals
- Vector search with HNSW indexing for semantic similarity across multiple embedding spaces
- ACID transactions ensuring consistency across all operations regardless of the modalities of data involved
This unified approach eliminated an entire category of integration complexity. There's no synchronization layer between a PostgreSQL metadata store and a Pinecone vector index. No S3 bucket management with foreign keys back to a relational database. No eventual consistency concerns when embeddings and metadata update at different times. Nothing had to be orchestrated manually. In fact, in ApertureDB, the schema, embeddings, and media coexist in one system accessible via a unified query language, and with transactional guarantees.
For the downstream AI agent, this architectural simplicity translates directly to reliability. In a fragmented stack (e.g., SQL + Vector DB + Graph DB), an agent must learn three different query languages and handle synchronization errors between them. With ApertureDB, the agent interacts with a single, consistent interface for graph, vector, and metadata operations. This reduces the complexity of the tool definitions and minimizes the 'reasoning gaps' where agents often fail. Moreover, passing in copious amounts of context is susceptible to 'context rot' and the quality of model response + finding relevant info (needle in a haystack) in a bunch of irrelevant context is a longstanding issue with LLMs. Adopting this approach allows us to preprocess the retrieved content as much as possible so we avoid polluting the LLM’s context window with a lot of unnecessary data. With the exponentially growing use of AI agents and agentic applications for various use-cases, ApertureDB is an incredibly powerful and versatile option for curating the data or memory layer for AI agents.
Data Layer Summary
The completed data layer comprises of:
- 280 Talk entities with 20+ queryable properties each
- 338 Person entities connected via 373 TalkHasSpeaker relationships
- 16,887 transcript chunk embeddings connected to parent talks with timestamp metadata
- Three descriptor sets optimized for different search intents
Every schema decision - separate Person entities for graph traversal, connected embeddings for constrained search, native date types for range queries, integer view counts for sorting - has been made with downstream LLM query patterns as the design constraint. The data layer doesn't merely store information; it encodes the traversal semantics that enable an LLM agent to translate natural language into precise database operations. Ultimately, the quality of an AI agent is capped by the structure of its data. By investing in a robust, multimodal knowledge graph on ApertureDB, we have moved beyond simple 'search' and created a structured environment where the agent can reliably perceive, navigate, and reason about the complex landscape of MLOps content.
In Part 2, we will demonstrate how these query patterns become the foundation for seven tools, and a ReAct agent that learns to select and compose them based on user intent. The sophistication of that agent's responses depends entirely on the foundation established here.
Complete source code is available on GitHub. ApertureDB documentation and API reference: docs.aperturedata.io. I would like to acknowledge the valuable feedback from Sonam Gupta (Telnyx), and Vishakha Gupta, in creating this Agent and blog.
Part 2 of this series
Ayesha Imran | Website | LinkedIn | Github
Software Engineer experienced in scalable RAG and Agentic AI systems, LLMOps, backend and cloud computing. Interested and involved in AI & NLP research.




















.jpeg)







.png)






