









Sometimes, our users are surprised: “What? You have a database but I cannot use SQL to query it?” (OK, that has now changed; more on that later.) Every once in a while, a few of them will follow that up with: “Well then you must support Cypher or GraphQL or Gremlin?” I usually take a deep breath and then launch into all the reasons why none of those worked for us, and I have had reasonable success in convincing people why they should give ApertureDB’s query language a chance. I have even had some users come and say: “Given all that your database supports, we now see why you needed to define a different query language” !
Before we can talk about query language for a multimodal AI database, what is a multimodal AI database? We did a deep dive on the true meaning of multimodality in this article. Fundamentally, a true multimodal AI database not only allows you to search with multimodal vector indexes but also helps you connect the dots between various modalities of data, manage it at scale, and lets you prepare or process the data in the format you need. Now let’s take a look at why existing database query languages were not enough for a multimodal AI database like ApertureDB, and why we built ApertureDB query language the way we did.
Popular Database Languages and APIs
SQL’s Staying Power Challenged By Multimodality
SQL has been around forever. People “claim” to love it, and some even swear off of any other database query language by not using databases that don’t offer a SQL query interface. Some convert other data models to SQL tables before retrieving the data they need! Then why did we even consider an alternative? What made us even think of a different query language? Let’s travel back in time and analyze the reasons that led to this decision. We can reuse some example queries we used back when we started building ApertureDB and had to make this choice as well as the ones we encounter now with Generative AI applications.
Imagine how you would implement the following queries:
- A user has shared a handbag image they like. Let’s show them similar handbags but the vendor wants to include only the handbags from the summer 2025 catalog and within 50-150$. Images should be the best angle and cropped to display.
- User typed a natural language query asking for highlights, pictures, video snippets, and a list of performers from a Taylor Swift concert attended by more than 20,000 people in midwest America. We need to modify all the data for display on the user’s browser.
Clearly the first part of both the queries fits right in with a multimodal vector search (you can learn more about that here) query which is now supported by not only some standalone vector databases, but also most of the popular relational databases. However, if you have a large catalog and 10s of millions of embeddings to search over, this may become a scaling issue for some incumbent databases. Ignoring that, the next step would be filtering the results of the vector search to apply the additional metadata constraints required by those queries. For a normalized relational database (which would be standard practice especially at large organizations), that means joins, likely two going into a catalog table and a product table for the first query and a concert table followed by performers’ table for the second. If there were no further constraints on how to choose the image or the other media, we would just retrieve the URLs and the display client (or a browser) could then fetch the multimodal data. However, we need to choose the best image and crop for the first query as well as prepare various media types for display in the second. This leads to another join query on the best image table followed by some OpenCV / FFMPEG access to prepare the data for display.
It’s this sequence of steps and onus placed on AI teams that made us question the current solutions. There had to be something better! After all, removing the need to do large Frankenstein DIY data solutions was what led us to building ApertureDB.
Even so, why then did we not try to make it work with SQL? JOINs already introduce quite some complexity into SQL. (Ever tried implementing graph traversals in SQL?) On top of that, we would have needed to introduce the ability to preprocess data, but with a wide range of preprocessing operations (along the lines of this research), which already meant breaking off from common SQL syntax. While extensions like PostGIS introduce new data types in SQL, we were looking into supporting a subset of existing operations that were really necessary for AI/ML applications on one hand and introducing a whole set of new data types on the other. It wasn’t just about retrieving a document, image, or video but the ability to look into the complex data type, express interesting components like bounding boxes in images or clips in audio/video, and the ability to process those. Together, it would have meant a much more extensive set of updates to the SQL standard.
Every time we would need to introduce a new data type to support, it would mean modifying SQL syntax. It would not only hurt the speed of our database development, it would do so without really remaining fully compatible with SQL and at the cost of continuing to propagate multiple JOINs as the best way of solving such queries, thus requiring expensive optimizations or hurting performance (after all, there is a reason why there is so much research on optimizing JOIN performance through views, query planning, and so on). Multimodality was the final nail in the SQL coffin for us.
TL;DR: We were not willing to give up performance, scalability, or our ability to build fast for the sake of retrofitting multimodal AI search and processing operations in a language built for structured row, column compatible data!
Graph Query Languages
Graph query languages like Cypher, Gremlin, GraphQL, SPARQL have also been getting attention lately and are really good with connected data. Cypher particularly does a decent job of being SQL look-alike but with ways to express traversals, and the others try to fallback to familiar object based access patterns. The languages here don’t limit complex searches which could offer users a great way to do data analytics provided the underlying graph database can scale and perform well which is not the topic of concern in this blog. Why then did we not adopt any one of these query languages ? Because we weren’t just building a graph database. It was an important requirement for us to support graph queries and the ability to store metadata, but it was also just as important to support vector search, data access, and data processing. While common graph databases have been introducing vector search extensions, a lot of those would have required our users to implement support for these functions.
Pythonic Query Interfaces
Pythonic querying, seen in tools like Pixeltable, Pandas, and SQLAlchemy, uses native Python syntax to build queries through method chaining and object-oriented logic. It’s flexible for handling multimodal or nested data and integrates well with ML workflows. In contrast, database query languages like SQL, SPARQL, or Cypher are declarative and optimized for engine-side execution, offering better performance for joins, indexing, and large-scale structured data. Pythonic methods are often slower and memory-bound unless backed by optimized runtimes, but they excel in downstream AI pipelines and schema-fluid environments. The choice depends on where computation happens and whether flexibility or throughput is the priority. Of course, most applications rely on a combination of the two whenever working with complex data at scale.
Evolving Communication Standards via Custom JSON
As machine learning and LLM pipelines increasingly rely on flexible, schema-light data flows, SQL’s rigid tabular structure becomes a bottleneck rather than a backbone. JSON, by contrast, has emerged as the lingua franca of evolving communication powering everything from ML labeling tasks to ETL workflows for LLM fine-tuning. Even the Model Context Protocol (MCP), designed to standardize context injection and memory across agentic systems, adopts JSON as its foundational format, reinforcing its role in scalable, interoperable AI infrastructure. Its nested, expressive structure aligns naturally with multimodal data and memory architectures, enabling dynamic updates, sparse fields, and semantic richness that SQL simply can't accommodate without cumbersome workarounds. Of course, we can’t throw any JSON structure at the service, and we still need to conform to a protocol defined in a verifiable JSON schema, but it is more easily customizable to a shape that can be validated.
Query Language and API for Multimodal Data
As we discussed earlier, legacy query interfaces were built for rows and columns, not for clips, frames, polygons, or multimodal context. If we are ultimately moving to natural language queries or voice AI interfaces, then why not use the interface that gives us the most flexibility and expressiveness to represent the various modalities of data, search, and operations in the database and build from there?
Breaking the Limitations of Legacy Interfaces – ApertureDB Query Language
We designed ApertureDB’s Query Language (AQL) to break free from traditional language constraints by adopting JSON as its native format. It is easy to read, extensible, and its verbosity was not a problem because we were dealing with larger data types which would be responsible for most of the query response times. It has allowed us to introduce data types and functionalities like image, video, embedding, clips, frames, polygons and intersections over unions (IoU) to find overlaps in interesting objects, leaving room for so many other modalities in the future. JSON also aligns with agentic workflows, supports sparse fields, and enables dynamic updates across modalities as we saw earlier.
Is it really easy in that case to gain adoption since it supports so much? Do new users not balk when they first see queries in AQL. Yes they sometimes do. However, as people gain familiarity with the syntax, it becomes simpler, and they often end up building their domain specific wrappers on it anyway (e.g. get_product_by_skuid() is a common e-commerce wrapper). Besides, we also offer other ways of accessing the database that acknowledge our users and applications, thus offering simpler interfaces that can be built on this more powerful JSON-based query layer. It’s the format that we predicted modern AI systems will speak and so we built our query language to speak it fluently. In this context, choosing JSON-first infrastructure isn't just a technical preference, it's a strategic shift toward systems that speak the language of modern AI.

Verticalization and Simplification of AQL
As discussed just above, AQL’s expressiveness means that first-time users may feel overwhelmed. That’s why we have a layered interface strategy: graphical frontends for visual query construction, Python object wrappers tailored to abstract classic AI operations, and simplified APIs that abstract complexity for application verticals. For developers and analysts, our Python wrappers offer object-oriented access to datasets, simplifying query logic and accelerating iteration. Together, these interfaces form a flexible ecosystem that respects user preferences while unlocking the full capabilities of our JSON-first architecture.These verticalized tools let users engage at their comfort level while preserving the full power of AQL underneath.
Multimodal UI
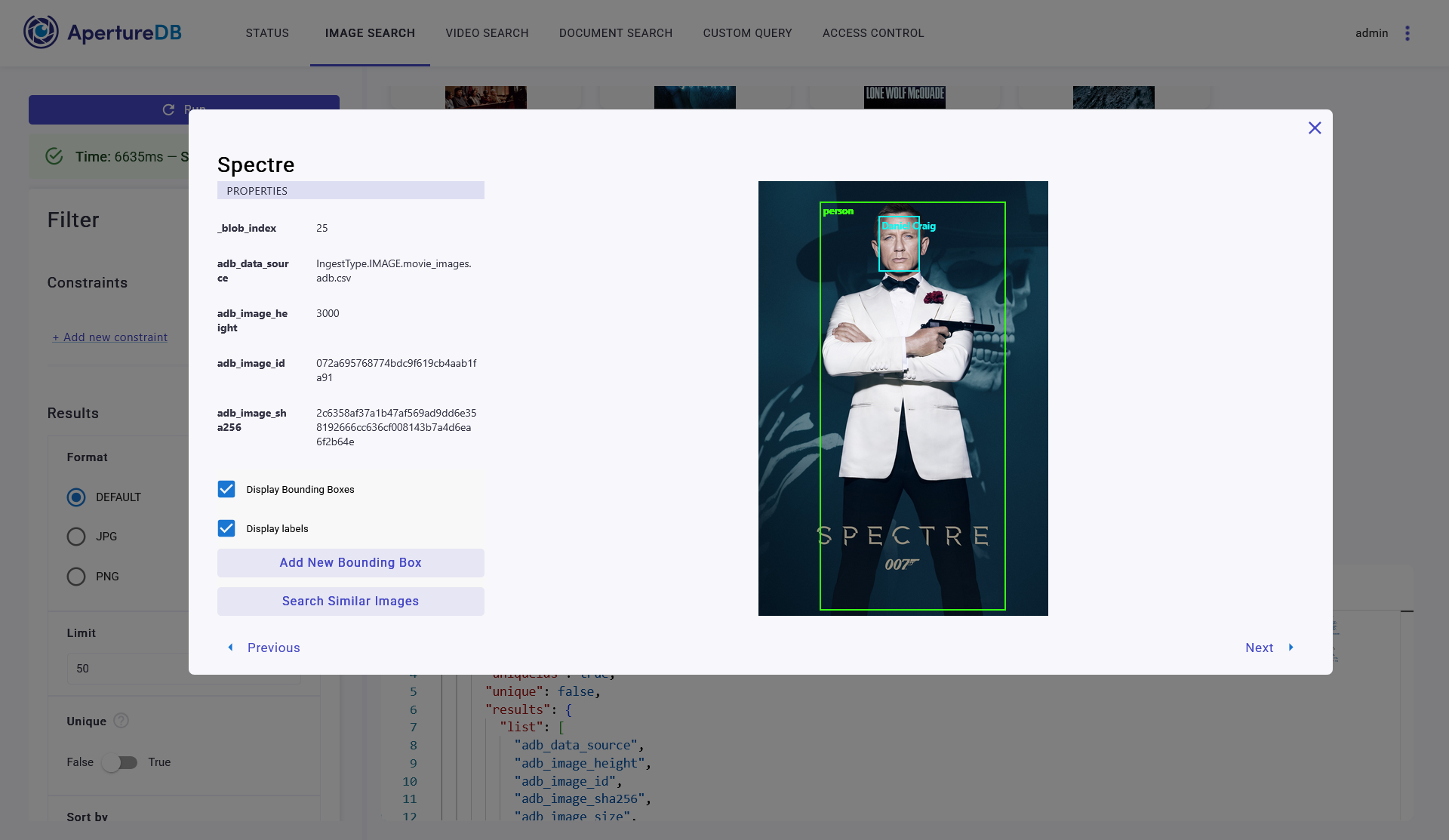
Multimodality is not easy to navigate beyond just sharing URLs around. If you want to navigate multimodal datasets, search them by natural language queries but not have to fight your tooling ecosystem to display them easily, you need a frontend that is built with multimodal data in mind. That’s exactly what ApertureDB UI is intended to do. You can do no-code searches for your images, videos, PDFs, run semantic searches across these data types, or use the graph schema to build your custom queries and visualize the results!

AI Workflows
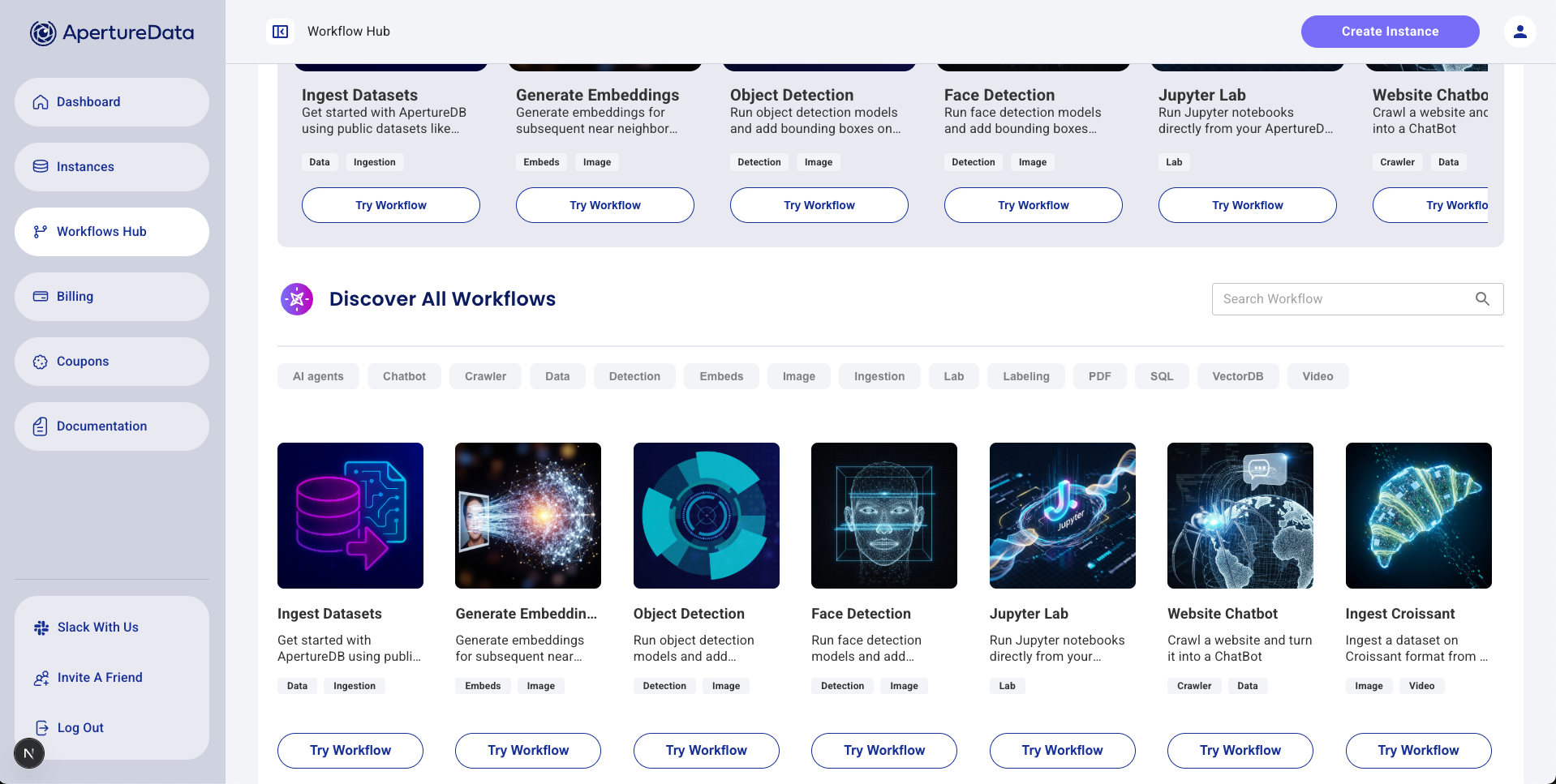
Aperture AI Workflows (covered in our earlier blog) provide a way to automate the execution of a commonly-performed task, when managing multimodal datasets for AI. They are structured sequences of operations designed to solve common AI/ML tasks like multimodal data ingestion, search, data correlation, or metadata filtering, using graph, vector, and multimodal-native capabilities offered by ApertureDB paired sometimes with models or services provided by partner tools. While it's easy to integrate ApertureDB with other software packages and create applications, AI Workflows take it a step further and allow you to create your applications by just placing blocks. These workflows are designed to be easy to use and can be customized to fit users’ needs.
Wrappers for the Reluctant – SQL and SPARQL
Not everyone wants to write JSON to begin with and they might be working with tools like BI dashboards that have better support for SQL. Some users come from SQL-heavy backgrounds or prefer declarative syntax for familiar workflows. We meet them where they are. ApertureDB supports SQL-style wrappers for structured queries, enabling users to interact with multimodal data using familiar paradigms. These wrappers translate SQL-like inputs into AQL under the hood, bridging the tools and syntax they already know while seamlessly extending into multimodal search and processing. For users from the RDF graph world, we also have SPARQL interfaces. As of now, these are read-only but that’s really where most of the user requirements are.
Not only does this new workflow allow users to use SQL to get information from ApertureDB, but it also gives a couple of other advantages. One is that it allows ApertureDB to be integrated into many dashboards and BI tools, such as Grafana and MetaBase, because they all have a PostgreSQL integration. Another is that it provides an on-ramp for a SQL user to learn the ApertureDB Query Language, using the built-in “EXPLAIN” feature of SQL to see the underlying query.
Next Step – Natural Language
With JSON as the foundation and layered interfaces in place, the next frontier is natural language and ApertureDB is already there. We’ve built retrieval-augmented generation (RAG) and GraphRAG chatbots that serve as natural language interfaces to ApertureDB. Our MCP server plugin enables agents and chatbots to inject structured memory and multimodal context directly into queries, grounding natural language interactions in precise, queryable semantics. This natural language layer doesn’t replace AQL, it builds on it. With its suite of JSON-based query language, Python wrappers, UI, and now natural language retrieval methods, ApertureDB has made access to multimodal data for AI pretty straightforward. Going forward, we will be focusing on improving the support for multimodality and knowledge graphs through our MCP server as well as building an Agentic memory layer to power future AI applications.
In closing, I would add, let the problem and its perfect solution prevail over a perceived language barrier!
Improved with feedback from Nolan Nichols (Stealth Biotech Startup), Drew Ogle, Sonam Gupta (Telnyx), Deniece Moxy, Gavin Matthews
Images by Volodymyr Shostakovych, Senior Graphic Designer




















.jpeg)







.png)






