









Remember when smart AI agents were mostly just a cool theory paper? Well, those days are over.
In Part 1, we explored why the right infrastructure—especially databases built for more than just plain text—is foundational for building capable smart AI agents. Because let’s face it: if your agent can’t process images, video, PDFs or other multimodal data , it’s not exactly ready for the real world.
In Part 2, we cracked open the “brain” of an agent and showed how multimodal data fuels richer reasoning, contextual understanding, and better decision-making. TL;DR: Smart data leads to smart actions.
Now in Part 3, we go beyond architecture and design into actual deployment—Agents in the wild. These aren’t cherry-picked demos or academic one-offs, but real-world projects, built by teams pushing the boundaries of what smart AI agents can do with ApertureDB as a core part of the stack.
Let’s take a closer look at how teams are making it happen.
Engineering An AI Agent To Navigate Large-scale Event Data
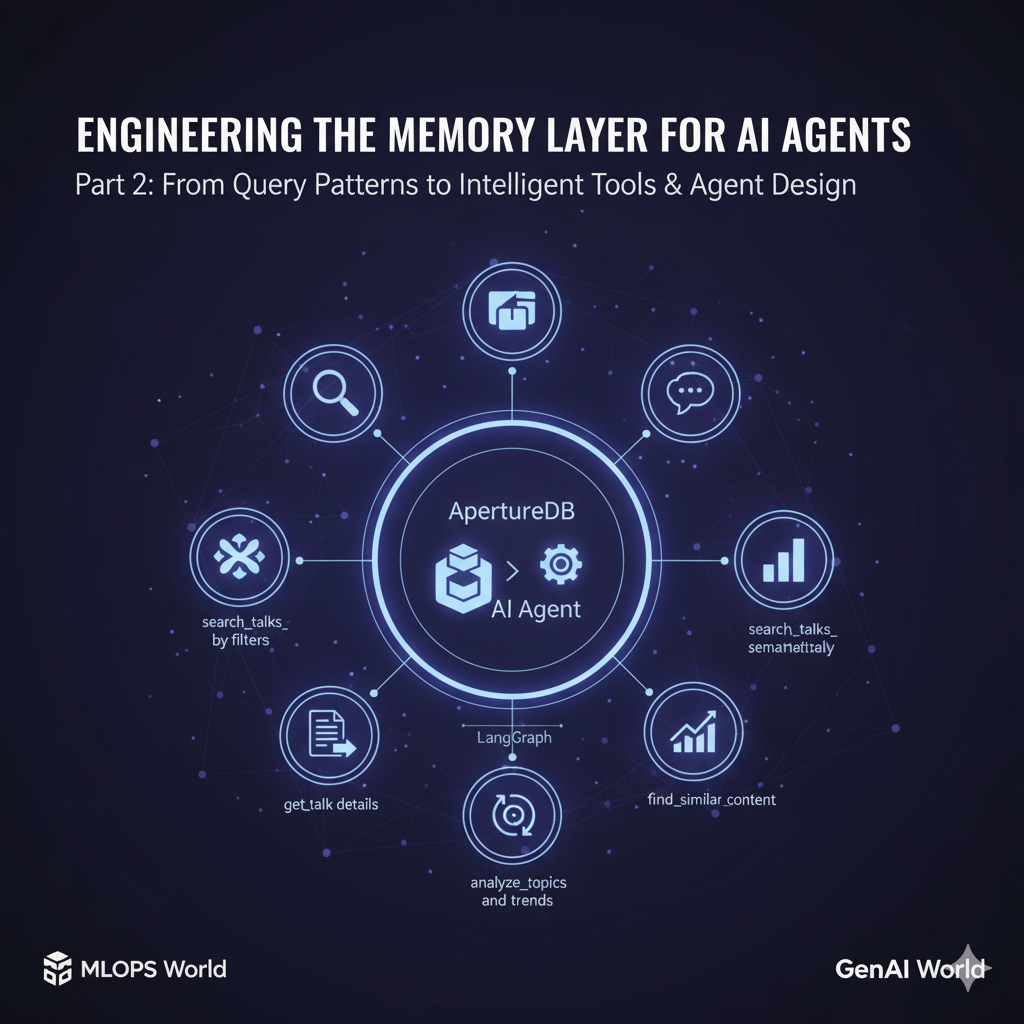
– Ayesha Imran, ApertureData Community Member
It’s not uncommon to have a collection of mixed data types like documents, slides, images, videos and their corresponding titles and descriptions dumped in folders or listed on webpages most commonly by dates and events. What if you don’t actually recall the year something was created? What if you wanted to cross-reference a few of those documents and descriptions based on some criteria or to find patterns? That’s what this agent is meant to solve.
To demonstrate the simplicity and flexibility of doing this, Ayesha chose the very common case of event data, in this case, with ApertureData partners, MLOps World.
The Workflow
- Design a schema that accommodates Talks, Speakers, Videos of the talks, and other existing information shared by the conference organizers.
- Use EmbeddingGemma from Google to embed talks and titles.
- Create and iterate on tools for the Agent to use and build the LangGraph-based ReAct agent with a NodeJS frontend for querying.
How ReAct Agent Leveraged ApertureDB
- Stored multimodal embeddings of talk description, speaker bio, talk titles, talk videos, and eventually talk PDFs / slides in ApertureDB .
- This unified approach eliminated an entire category of integration complexity. There's no synchronization layer between a PostgreSQL metadata store and a Pinecone vector index. No S3 bucket management with foreign keys back to a relational database. No eventual consistency concerns when embeddings and metadata update at different times. Nothing had to be orchestrated manually. In fact, in ApertureDB, the schema, embeddings, and media coexist in one system accessible via a unified query language, and with transactional guarantees.
- For the downstream AI agent, this architectural simplicity translates directly to reliability. In a fragmented stack (e.g., SQL + Vector DB + Graph DB), an agent must learn three different query languages and handle synchronization errors between them. With ApertureDB, the agent interacts with a single, consistent interface for graph, vector, and metadata operations. This reduces the complexity of the tool definitions and minimizes the 'reasoning gaps' where agents often fail. Moreover, passing in copious amounts of context is susceptible to 'context rot' and the quality of model response + finding relevant info (needle in a haystack) in a bunch of irrelevant context is a longstanding issue with LLMs. Adopting this approach allows us to preprocess the retrieved content as much as possible so we avoid polluting the LLM’s context window with a lot of unnecessary data. With the exponentially growing use of AI agents and agentic applications for various use-cases, ApertureDB is an incredibly powerful and versatile option for curating the data or memory layer for AI agents.
The Result
The completed system demonstrates what becomes possible when data architecture, tool design, and agent orchestration are aligned toward a common goal as described in a two-part blog series. The graph schema from Part 1 enables the traversals that power speaker analytics. The connected embeddings enable constrained semantic search. The parameterized tools expose these capabilities to an LLM that can reason about user intent and compose operations autonomously. Each layer builds on the previous, and the result is an intelligent search interface described in Part 2 that handles complex, multi-faceted queries about MLOps conference content. Not only that, but a similar series of steps can easily be adopted for other such scenarios.
The best part, you can test the application yourself and use the steps outlined or the code to build your own. The full source code is available on GitHub.
Agentic RAG with SmolAgents: Smarter Search That Thinks for Itself

—Haziqa Sajid, Data Scientist
Vanilla RAG has a fatal flaw: once it retrieves bad results, it’s game over. No retries, no corrections, no hope. Enter Agentic RAG—a smarter way to search. Built using Hugging Face’s SmolAgents and powered by ApertureDB, this project by community member Haziqa Sajid tackles academic paper overload.
By giving RAG a brain and the ability to reason, it brings structure and clarity to a sea of information. Instead of relying on brittle keyword search, this smart AI agent refines queries, reruns searches, and even shifts strategies if results fall short.
The Workflow
- Extracts information from complex, multimodal documents (like PDFs).
- Allows agents to re-ask, refine, and retry when they hit a dead end.
- Links semantic memory with structured metadata—crucial for good retrieval.
How The System Uses ApertureDB As The Brain the Brain Behind The Agent
- Store vector embeddings from academic PDFs
- Enable multimodal retrieval (text, structure, even metadata)
- Provide context for LLMs to reason more accurately
The Result
A research assistant that doesn’t hallucinate—it finds actual answers, complete with citations. Whether you are looking for papers on Type II Diabetes or troubleshooting obscure medical treatments, this agent can crawl, adapt, and deliver.
This is not a trivial demo, but an easy to productionize, agent-powered research system. A template for anyone building smarter knowledge copilots, with a unified multimodal memory at its core. Exactly what ApertureDB was purpose built for.
📖 Read the blog
People Coming Over – The Personalized Agent That Shops So You Don’t Have To

— Team People Coming Over
We have all been there: guests are coming over, your room looks sad, you are not alone. There is even a subreddit about it: r/malelivingspace.
But instead of browsing IKEA or hiring an interior decorator, you snap a photo and let your AI agent handle it.
This is People Coming Over, an image-to-action agent that analyzes your room and makes it better.
The Workflow
- Perceive: You upload a photo of your space.
- Understand: The agent uses vision models to detect layout, objects, and overall vibe — clean, cluttered, cozy, chaotic?
- Plan: It reasons about improvements: “Add a floor lamp here,” “Move the couch closer to the window,” or “Swap the art for something brighter.”
- Act: It generates a shortlist of products and links to buy them, based on your preferences and budget.
Why ApertureDB?
Behind the scenes, this agent needs to store and correlate:
- Input photos
- Object detections and layouts
- Embeddings for visual similarity search
- LLM-generated suggestions and reasoning chains
- Product metadata and user preferences
That is a lot of heterogeneous, linked data, and it has to be queried in-memory, in real-time, as the agent reasons and responds. With ApertureDB:
- Images, metadata, embeddings, and text are stored together in a single multimodal graph.
- The smart agent performs cross-modal search — e.g., “Find couches that look like this and match this vibe.”
- Latency stays low, because data is retrieved in milliseconds, not stitched together from S3, Redis, and Postgres or other third party tool configurations.
The Result
A multimodal shopping experience powered by ApertureDB. It is like having a design expert, research assistant, and fulfillment coordinator rolled into one. But instead of juggling three apps and ten browser tabs, a single agent handles everything—from analyzing your space to recommending products and managing orders—at a fraction of the cost. No duct tape. No hacks. Just fast, intelligent decision-making—built on ApertureDB, the data foundation purpose-built for Agentic AI.
🔗 Explore the project
Metis AI – A Browser Agent That Automates SaaS Tasks

— Team Metis
SaaS tools are everywhere—but learning how to use them still feels like a chore. Metis AI aims to change that.
The Workflow
- Scrape how-to docs, screen recordings, and video tutorials.
- Convert them into multimodal instructions using ScribeAI.
- Store those instructions in ApertureDB as vectorized memory.
- Use Gemini to match user intent to the right actions, then execute them.
Unlike other agents, Metis can perform complex, multi-step actions on SaaS platforms by grounding its understanding in prior examples.
ApertureDB Plays A Critical Role In:
- Storing and retrieving image+text-based guides for the web agent.
- Enhancing agent memory to complete tasks more accurately.
- Tracking agent performance using Weight & Basis Weave evaluator.
The Result
By leveraging ApertureDB, Metis’ AI team enhanced the performance and capabilities of a web agent by augmenting it with prior knowledge of the platform. Using tutorial videos, generated structured instructions for a multimodal agent, enabling it to:
- Execute multiple steps in response to a single customer query
- Incorporate prior context to improve task execution
- Track accuracy using an evaluator component integrated with W&B Weave
🔗See The Tech Behind Metis
ApertureDB Makes Agentic AI Work—At Scale
What once felt like science fiction—agents that see, reason, and act—is now very real. Across these four projects, we have seen how developers are moving beyond prototypes and academic papers to deploy production-grade AI agents that actually do the work.
From automating SaaS workflows to decoding research papers, redesigning living rooms, and navigating complex interfaces like a human, one common thread runs through them all: ApertureDB.
It is the memory layer that enables agents to retain, retrieve, and reason across multimodal data— videos, images, text, structure, embeddings, and metadata—at scale and in real-time. No brittle pipelines. No fragmented stores. Just a unified, queryable system built for agents that need to think fast and act smarter.
The future of AI isn't just large models—It is intelligent agents with the power to reason, recall, and respond. ApertureDB is how you build them.
👉 Start your free trial of ApertureDB Cloud and give your agents the memory they deserve.
Part 1: Smarter Agents Start With Smarter Data
Part 2: Your Smart AI Agent Needs A Multimodal Brain




















.jpeg)







.png)






