









The recent wave of writing on context graphs, like Foundation Capital’s Context Graphs: AI’s Trillion‑Dollar Opportunity has correctly identified something important: we’re entering a world where decisions made by humans and agents need to be captured, understood, and revisited with far more fidelity than today’s systems allow. But the conversation so far has been mostly conceptual.
If context graphs are going to become the system of record for reasoning, then we need to confront the messy reality of how decisions are made, how they’re justified, how they’re corrected, how they are represented, and how they’re judged in hindsight. As Travis Thompson writes in Modern Data 101’s Context Graphs and the Future of AI: “Without access to decision-time context, intelligence stalls at insight and never translates into autonomy. The reasoning that turns data into action dissolves into chats, calls, and memory.” DataOS is an example of how to represent this Judgment in order to make Context Graphs a reality, which answers one part of the equation.
The harder questions, the ones that determine whether context graphs can actually exist inside real organizations and how, are still sitting in the shadows. And we need the technical substrate to support all of that at scale. This blog is about the questions we must answer before context graphs can move from theory to practice.
Tracking How Decisions Were Made and Were They Really Right
A context graph shouldn’t just store the decision. It should store the entire reasoning environment:
- What information was considered
- What alternatives were rejected
- What assumptions were made
- What environmental factors were present
- Who made the call
- And later, whether the decision turned out to be correct
This last part is where context graphs become transformative.
If an agent proposes Option A and a human chooses Option B, the system should later be able to say which one was better and why. This is how organizations, and agents, can learn and evolve to be better than the status quo, not just more efficient.
A simple diagram helps illustrate the idea:
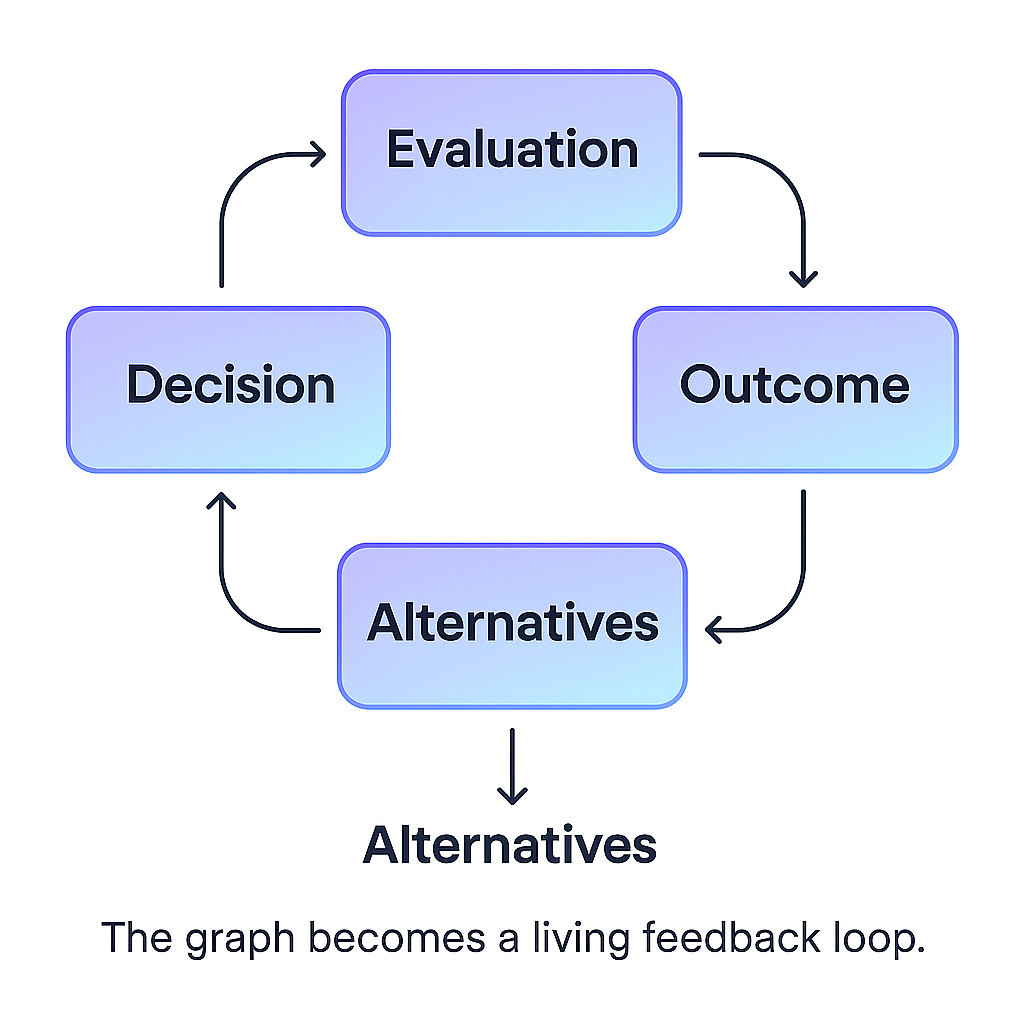
Who Gets to Grade the Reasoning?
If agents are going to generate decision traces, humans must be able to review them before they become canonical. Otherwise, the system of record becomes a hallucinated history.
This introduces a new kind of workflow, something closer to code review than traditional business process:
- A decision is made
- A trace is generated.
- A human validates, corrects, or expands it
- The trace becomes part of the organizational memory
This isn’t optional. It’s governance.
Just as pull requests require comments and approvals, and CRM opportunities require “closed won/lost” reasons, decision traces need structured, expected human input. The organization must develop reason hygiene, a cultural expectation that decisions come with explanations.
The Language of Reasons: Understandable to Humans and Agents
Natural language is too ambiguous. Pure structure is too rigid. The right answer is a hybrid: short explanations written by humans or agents, paired with structured tags that capture meaning in a machine‑interpretable way.
Something like:
Reason: "We chose Vendor X because they could deliver in 3 weeks." Tags: [timeline_pressure], [vendor_reliability], [budget_neutral]
This dual representation ensures that:
- Humans can read it
- Agents can reason over it
- Meaning doesn’t drift over time
Capturing Environmental Context
I met the CEO of a company last year working on beauty GPT. At the beginning it seemed like a fairly simple recommendation problem when someone comes looking for the right lipstick shade. But then he made me see why it was not just about the product description but about the customer’s skin type, medical history, time of day when the lipstick would be used, and most surprisingly at first but then totally understandable, weather conditions! If you pause to think about it, this maps very closely to how we make choices on a day to day basis, just subconsciously sometimes. Similarly, a decision made during a hiring freeze is not the same as a decision made during a growth phase. A pricing change made during a bull market is not the same as one made during a downturn.
Context graphs must be time‑aware and environment‑aware. They need to ingest:
- Market conditions
- Funding status
- Organizational constraints
- External signals
- Written and unwritten norms
Without this, we risk judging past decisions with present‑day hindsight bias.
Honesty, Fear, and the Legal Layer
Some decisions, especially around performance, hiring, or termination, carry legal and cultural weight. People often know the real reason but cannot write it.
If context graphs become the system of record, we need:
- Protected fields
- Redaction layers
- Role‑based visibility
- Anonymous or semi‑anonymous channels
- Clear separation between operational context and legal context
Otherwise, people will self‑censor, and the graph loses ground truth.
Can Context Graphs Be Standardized?
To a degree. The underlying schema can be shared, but every company has its own vernacular:
- “Wartime mode”
- “Tier 1 customer”
- “Leadership alignment”
These phrases carry cultural meaning that outsiders, and agents, won’t understand without translation.
Context graphs must support both shared ontologies and local ontologies, with dynamic mapping between them.
Scale, Performance, and the Need for a Real Data Layer
If context graphs are going to be the backbone of organizational intelligence, they must support:
- Billions of nodes and edges
- Real‑time writes from agents
- Fast traversal across time and teams
- Adds, updates, and deletes at massive scale
- Integration with the rest of the knowledge base
This is not a toy problem. It’s a database problem, a systems problem, and an organizational problem all at once.
Where ApertureDB Fits: The Foundation for Context Graphs
This is where ApertureDB becomes relevant. It provides the technical substrate that context graphs require but that most existing systems simply cannot deliver.
ApertureDB’s architecture fuses graph storage, vector search, metadata, and multimodal assets into a single system. That matters because context graphs aren’t just graphs, they’re a blend of:
- relationships
- embeddings
- documents
- temporal metadata
- agent traces
- human annotations
- other multimodal objects relevant to the decision making process
ApertureDB handles this natively, without forcing you to stitch together a graph database, a vector store, a blob store, and a metadata layer.
It also supports the ingestion velocity required for agent‑generated context. Agents produce traces at machine speed; humans don’t. The database must keep up with both.
As context is time‑bound, ApertureDB’s support for explicit versioning, timestamps, and lineage allows you to reconstruct the exact environment in which a decision was made.
A simple conceptual diagram:
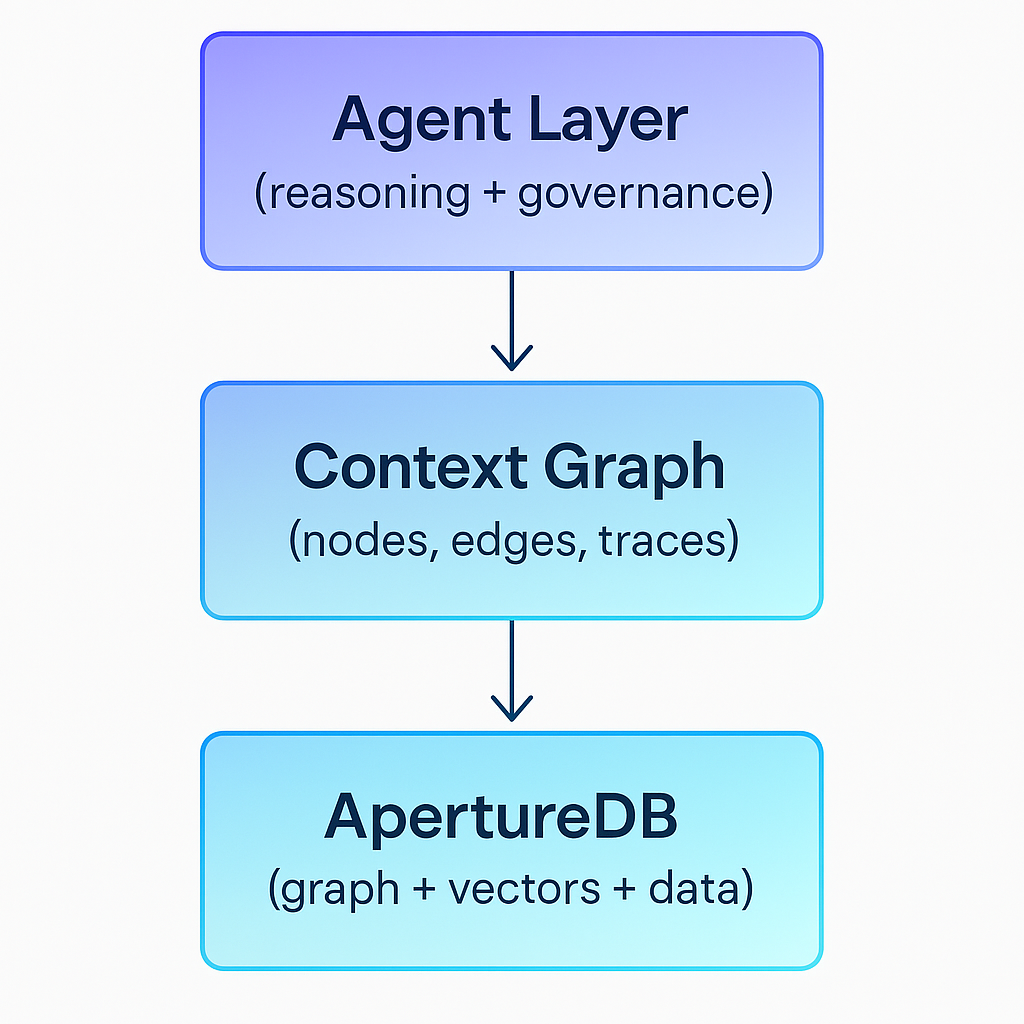
Why You Still Need an Agentic Layer
ApertureDB gives you the storage, the speed, and the multimodal capabilities. But context graphs require an agentic reasoning layer that can:
- generate decision traces
- evaluate alternatives
- enforce governance
- request missing context
- translate human vernacular into structured meaning
- compare outcomes over time
This is the layer where the organization actually becomes smarter.
And You Need Integrations Everywhere
A context graph only becomes rich if it’s fed by the tools where work happens:
- Slack
- CRM
- ATS
- GitHub
- Notion
- Ticketing systems
- BI tools
- Agent frameworks
Every tool becomes a context emitter. Every agent becomes a context consumer. Every decision becomes a node in the graph.
Without this, you end up with an empty graph—beautiful in theory, useless in practice.
Pruning, Summarization, and the Life Cycle of Context
Not all context is worth keeping forever. Some decisions matter for years; others matter for a week. The system needs:
- retention policies
- automatic summarization
- archival layers
- deletion workflows
A context graph that never prunes becomes noise.
Conclusion: Context Graphs Are a Cultural Shift, Not Just a Technical One
The technology is emerging. ApertureDB provides the substrate. Agent frameworks provide the reasoning. Integrations provide the raw material.
But the real challenge is cultural.
Organizations must learn to:
- justify decisions
- annotate reasoning
- evaluate outcomes
- embrace transparency
- build shared ontologies
- protect sensitive context
- and treat decision traces as first‑class artifacts
If we get this right, we’ll build organizations where:
- agents understand human reasoning
- humans understand agent reasoning
- decisions become auditable
- knowledge compounds
- and the entire company becomes more intelligent over time
That’s the real trillion‑dollar opportunity!
Improved with feedback from Matthias Spycher (Fanatics), Sonam Gupta (Telnyx), Heidi Hysell (Future Future)



















.jpeg)







.png)






