









Applying the Knowledge-Memory-Context (KMC) Blueprint to the 2026 AI Cognition Landscape
This is Part 2 of a series on memory and cognition. Part 1 — Human Memory: The Perfect Template for AI Memory established the human memory model as the analytical lens for evaluating AI memory and cognition systems.
We have split this Part 2 in three different posts to allow us to capture valuable details and insights for future decision making.
In this blog, we outline what AI cognition means, establish standard metrics, and introduce the frameworks / tools we have have included in our study. This forms the baseline to understand what’s out there as it’s a rapidly growing market to address a need for Agentic cognition and reasoning.
The report on full framework-by-framework analysis will cover 20+ frameworks against 8 characteristics established in this post.
In the last part, we will establish some criteria that our readers can use to map their requirements to the right framework and make an informed choice for their AI deployments.
This study is a collaborative effort between ApertureData and Ali Nahm, Partner at Tribe Capital. By combining ApertureData’s focus on multimodal data infrastructure with Tribe Capital’s data-driven approach to analyzing the AI ecosystem, we’ve evaluated 20+ frameworks to help architects and leaders navigate the move from simple RAG to true machine cognition.
Is It Memory, Context, or Cognition?
The hardest part of this analysis was agreeing on what we were evaluating.
“Memory” means something different in every framework in this landscape. For Letta, it’s a stateful agent that is personalized and improves over time. For Claude, memory is a markdown file a developer can read and edit. For Mem0, it’s a fact store where an LLM decides whether incoming information should create a new record, update an existing one, or be discarded. Then LangChain talked about Cognitive Architecture to capture how your AI system “thinks”. None of these are wrong. They’re designed for different problems. The mistake is evaluating them against the same standard without saying what that standard is.
Our standard -- organizations’ deployment requirements: multiple users (potentially across departments), multiple sessions, knowledge that is shared when permissible and compounds across teams, and outcomes that must be traceable. That’s the use case we’re evaluating for, not because it’s the only valid one, but because it’s the unmet need we’re focused on.
Why Agentic Cognition Matters
Before we dive into the details though, why does memory or cognition matter for enterprise AI at all? As employees, our memories, knowledge base, and occasionally our experiences, are what determine most of the actions we take on a day-to-day basis.
The use cases in the ever-exploding AI or now agentic world are similarly concrete and varied, especially as AI agents increasingly become our colleagues or teammates. A support agent that remembers a customer’s history across every previous ticket, not just the current conversation, can deflect escalations before they happen. A sales agent that tracks deal context, stakeholder relationships, and what was promised in the last call can personalize outreach without briefing from a human. A compliance agent that knows which policies changed last quarter can answer “what did we know, and when?” with an audit trail, not a guess.
The pattern across these: memory acts as the consolidation engine that converts high-velocity, stateless interactions into a durable institutional nervous system. In this model, an interaction is no longer an "incidence to be addressed in isolation”, but a "signal to be synthesized”. By the time an agent handles its next ticket, it isn't just retrieving a file; it is operating from a refined baseline of organizational intelligence.
Agentic or more generally AI memory also enables capabilities that don’t exist in stateless architectures:
- Cross-session continuity: an agent that resumes a multi-week project without needing to be re-briefed
- Cross-agent knowledge construction and sharing: a research agent surfaces a finding that a downstream summarization agent uses without human transfer and establishes a relationship between the relevant concepts. These agents can certainly be a mix of human and AI!
- Organizational learning: patterns from thousands of support interactions inform how agents handle the next ticket, without retraining and perhaps capture the outcome to learn from it with human-in-the-loop as needed
- Temporal and environmental reasoning: an agent that knows when a policy changed, not just what it says today or what circumstances is it valid under
- Compliance and audit: regulatory answers backed by a traceable record of what the agent knew and when
An agent that acts just on a collection of files without organizational knowledge and user learnings is a search engine with a chat interface. An agent built with cognitive capabilities is closer to a colleague, one that remembers what you told it, learns from experience, and builds intelligence over time.
For enterprise AI specifically, the stakes are higher than for consumer applications. Enterprise agents touch decisions that have consequences: procurement, customer relationships, compliance reporting, clinical recommendations, and other such high-impact tasks. Memory without cognitive lineage, the ability to trace a decision back to the specific user, session, and raw input that triggered it, can become a liability. In regulated industries, an agent's "recommendation" is only as good as its traceable history.
The Logic of Machine Cognition: Knowledge, Memory, and Context
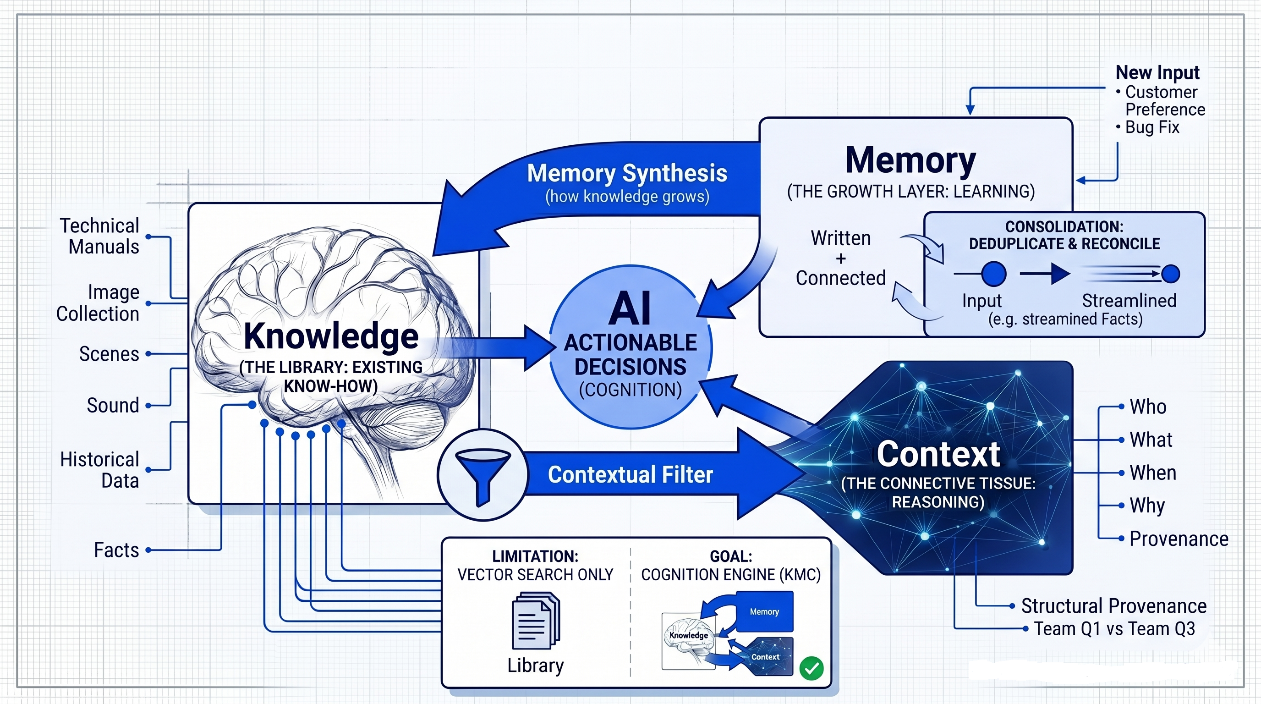
Memory, even though a simple representative word, is not a simple concept. In our research at ApertureData and Tribe Capital, Ali Nahm and I found that "Memory" is often used as a catch-all term that obscures more than it explains. Cognition or Intelligence is what enables the actual decision-making, and it requires a combination of existing knowledge, new memories, and relevant context to enable the right AI-enabled actions. Therefore, to evaluate our current set of 20 frameworks, and to help architects parse the noise, we’ve codified the Knowledge-Memory-Context (KMC) blueprint. This isn't just a technical stack. While the industry often uses these terms interchangeably, they represent three distinct layers that must interact for an AI to "think" like a colleague:
- Knowledge (The Library): This is the Existing Know-How. It includes your technical manuals, collection of images, audio recordings, historical data, and established facts. It is the static baseline the agent starts with.
- Memory (The Growth Layer): This is the Learning Layer. It is the agent’s ability to take new experiences—a customer's preference or a bug fix—and "write" them as well as “connect” them into the system. Crucially, this layer must handle consolidation (deduplicating and reconciling new facts with old ones) so the knowledge base grows rather than just gets cluttered.
- Context (The Connective Tissue): This explains the Reasoning. It answers the Who, What, When, and Why. Context connects a piece of Memory to a specific point in the Knowledge graph. It provides the structural provenance, allowing the agent to know that Fact A applies to the Marketing Team in Q1, but might be irrelevant for the Legal Team in Q3.
How They Connect: Cognition occurs when these three layers are in a constant loop. Context filters your Knowledge to make it relevant to the current task, while Memory constantly feeds new updates back into that Knowledge base.
By understanding this loop, you can see that a framework that only does "Vector Search" is essentially just a Library, not human brain using the knowledge to guide useful actions. A true Cognition Engine manages the entire cycle.
How We Evaluated: The 8 Characteristics
With our KMC blueprint in mind, we distilled 8 characteristics that define a true cognition engine for organizational intelligence, and evaluated every framework against these eight characteristics. Here is what each one measures and why it matters for organizational intelligence.
1. Multimodality
What input types does the framework natively store and retrieve, not just process and discard?
Our brains are not tabular or text-only. We take in a variety of signals comprising our intelligence. For true enterprise cognition, the asset must be a first-class memory resident. When a clinical or architectural agent "remembers" a diagram, it shouldn't just remember the description; it should be able to semantically query the features of the asset itself to detect patterns a text description would miss, and be able to retrieve the object itself.
2. Cognitive Architecture
What is the supported memory model and does it track context as a first-class concept?
Human memory has distinct types: episodic (what happened in a specific session), semantic (general knowledge accumulated over time), and procedural (how to perform a task). Enterprise AI systems need all three. But the deeper gap is context, the organizational provenance of a memory. Who captured this? In which session? For what purpose? Under which team and organization? What was the outcome? Without context as a first-class concept, retrieval is search. With it, retrieval is cognition.
3. Knowledge Graph & Search
Does the framework represent relationships between memories, not just similarity?
Vector similarity retrieval answers: “what is most similar to this query?” Graph-native retrieval also answers: “what is connected to this entity, and how?” For enterprise use, where customers have histories, business decisions matter, products have relationships, and decisions have dependencies, the relational structure of knowledge matters as much as semantic similarity. Hybrid retrieval (vector + graph + keyword) is the model that serves enterprise requirements.
4. Storage Backend
How does the framework actually store the memory data?
This matters for four key enterprise concerns. First, vendor lock-in: a closed proprietary store means your organizational memory is held by a third party. Second, performance: the storage layer determines retrieval latency and scale. Third, compliance: some enterprises require that their data never leave their infrastructure, which means, backends’ support on-prem or VPC deployment matters. Finally, the more data pieces you have to connect to achieve the functionality, even if hidden behind an API, it has implications for security, performance, cost, debuggability, and scale.
5. Sharing Model
How is memory scoped and shared – by user, session, team, department, or organization?
User-level memory is table stakes. Personal assistants have had this for years. Enterprises need additional levels: team-level memory, project-level, and org-level memory.
6. Performance & Scale
What do we know about retrieval latency, throughput, and scale?
Enterprises require performant memory frameworks for production use-cases. Memory lookups must be fast for a delightful customer-facing interactions. Frameworks cannot degrade at 1M memories.
7. Memory Operations
How does the system incorporate new information?
The choice of memory operation model is the choice of how long the system stays useful. For long-running enterprise agents, this is not an implementation detail; it’s the design decision that determines whether the system works at month 12 the way it did at day 1.
8. Governance
Can the historical state be preserved, is queryable, shows its evolution, and can be deemed immutable if necessary?
Regulated industries require an agent memory system with an audit trail. They need to be able to answer “what did the agent know when it made that recommendation?” For unregulated industries, lineage still matters to undo incorrect memories. Frameworks that overwrite memories rather than preserving history make this impossible.
The Four Camps
The landscape splits into four categories, each with a distinct take on what’s necessary.
- Memory-first products: memory is the core value proposition. Some examples in this category are Mem0, Zep, Graphiti, Cognee, Letta, Hindsight, MemMachine, Prem Cortex, RippleTide, Sentra, Lyzr, aperture-nexus. The strongest technical diversity is here, and the sharpest differences in what “memory” means. Some are built for individual agent developers; a few target enterprise scale from the start.
- Agent frameworks with memory: memory is one component of a broader orchestration system. LangGraph, Mastra, CrewAI, and Agno offer this. These represent how most teams first encounter memory, not as a dedicated layer, but bundled into the framework they already use. The cognitive model is either absent or delegated to storage backends. Teams that start here typically rebuild the memory layer as requirements grow.
- Model-native memory: memory tied to a specific provider’s product for instance Claude Memory, OpenAI Memory. In a lot of these cases, memory is tied to the provider unless you go through some translation hoops. e.g. you cannot use OpenAI memory with Claude or vice versa. They define what “good enough” looks like for single-provider deployments. The moment requirements touch multimodality, cross-team sharing, lineage, or model portability, they run out of road quickly.
- Specialized / research: active research and specializations. We found examples like MemoryOS (EMNLP 2025 Oral, Beihang University), MemPalace (released April 2026, viral, benchmark-contested). Academic and experimental systems not typically targeting large-scale production under their current state. These are mentioned because they can influence production systems and because the architectural ideas are worth understanding.
These are the frameworks we have included in the study that we will be releasing next week.
Ali Nahm is a Partner at Tribe Capital. aperture-nexus is built by ApertureData. Both authors have positions in this landscape. We’ve disclosed them in the framework scoring and welcome challenges to our assessments.
This blog was improved with feedback from Sonam Gupta, Sr. Dev Advocate at Telnyx




















.jpeg)







.png)






